Project update 10 of 20
Programming the AIR-T: SIMPLICITY! (1 of 2)
We want the AIR-T to be simple & powerful and from our founding that has been our mission:
*merge AI with wireless systems.*
If you are considering the AIR-T for your wireless machine learning, digital signal processing, or high-performance computing application, you will need to know how to program it. In this series of updates, we will discuss some of the details of how to program the AIR-T, what the different programming APIs are, and how we simplify the whole process, allowing you to get your algorithm up and running quickly.
Everyone on our team has worked on large-scale wireless systems, most of which are based on SDRs, so we understand many of the headaches with development and deployment of such systems. The AIR-T is designed to reduce the number and effort of engineers required to create wireless systems and create more powerful wireless systems.
One limitation we’ve found is that you really need a large team due to all of the disciplines involved with SDR. As an example, you need firmware engineers to handle programming the FPGAs, software engineers to control the hardware and extract/process the data, and digital signal processing engineers to develop the math behind the associated algorithms. The challenge of an idea like the AIR-T is that we now add all the associated disciplines of machine learning and AI into the mix as well.
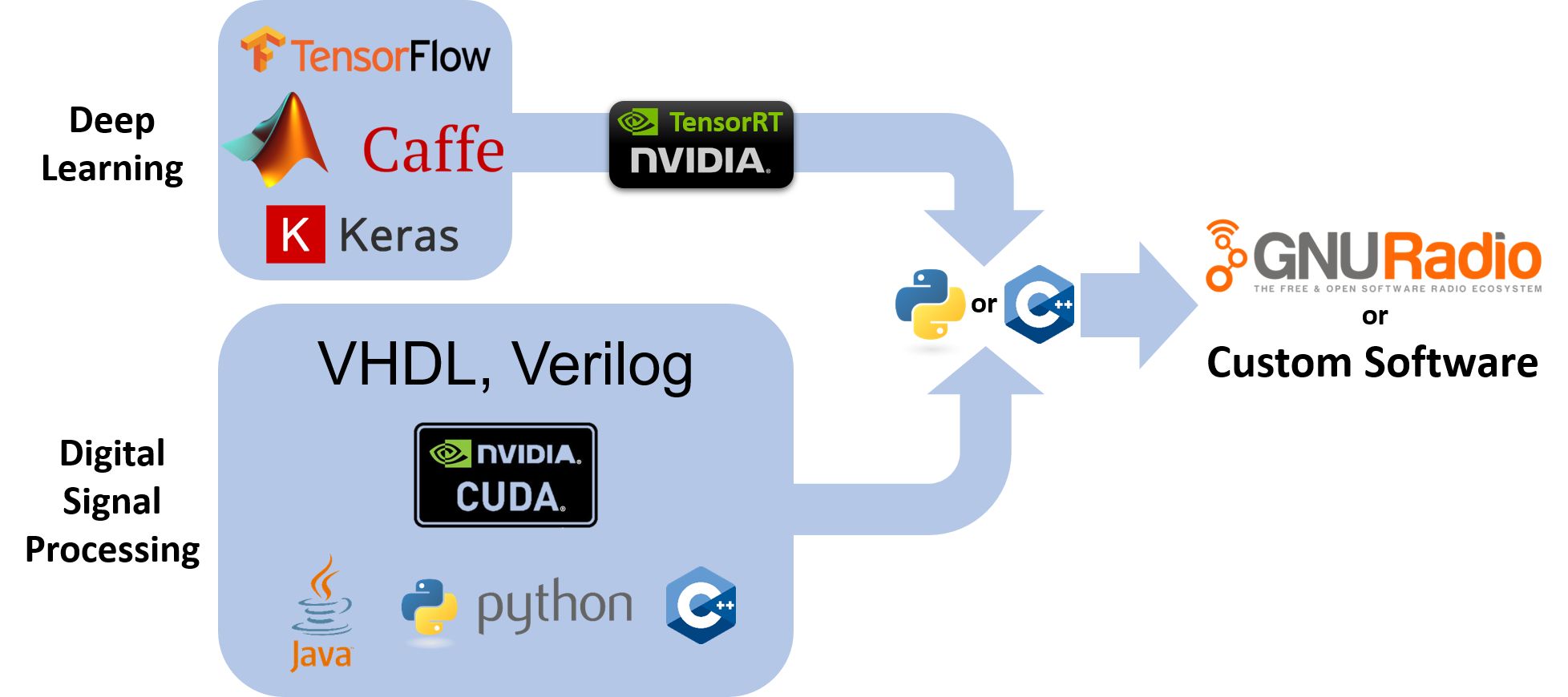
Our goal is to make programming the AIR-T as simple and streamlined as possible. At a minimum, you will need knowledge of how your algorithm works and you will need to be able to program in a lanugage like Python, but you won’t have to worry about things like buffering, threading, talking to registers, etc. For power users or those wanting to get every last percentage of performance out of the device, various drivers and hardware abstraction APIs will be provided so you can write your own custom application. However, this use case is not required to develop, test, and deploy your algorithm. We anticipate the vast majority of customers will be able to quickly prototype their algorithm using a GNU Radio-based workflow and then not have to do any additional steps in order to optimize their application further.
Machine Learning Deployment
For those of you unfamiliar with machine learning algorithms, the process is typically broken up into two pieces: training and inference. Rather than rewriting any of the great references cover both of these, here is an excellent blog that discusses training and inference and here is a great introduction to how neural networks operate.
The AIR-T is designed to be an edge-compute inference engine for deep learning algorithms, therefore a trained algorithm will be necessary to use the AIR-T for deep learning. You will either need to create and train one yourself, or obtain one through a third party. Many are publicly available as well. The easiest way to execute a deep learning algorithm on the AIR-T is to use NVIDIA’s TensorRT inference accelerator software. By providing support through our strategic partner, NVIDIA, we enable you to deploy AI algorithms trained in TensorFLow, MATLAB, Caffe2, Chainer, CNTK, MXNet, and PyTorch. The procedure is outlined in the following flowchart, where a deep neural network (DNN) is used. Note that if you are using an algorithm that is already trained, the first two steps will be bypassed.
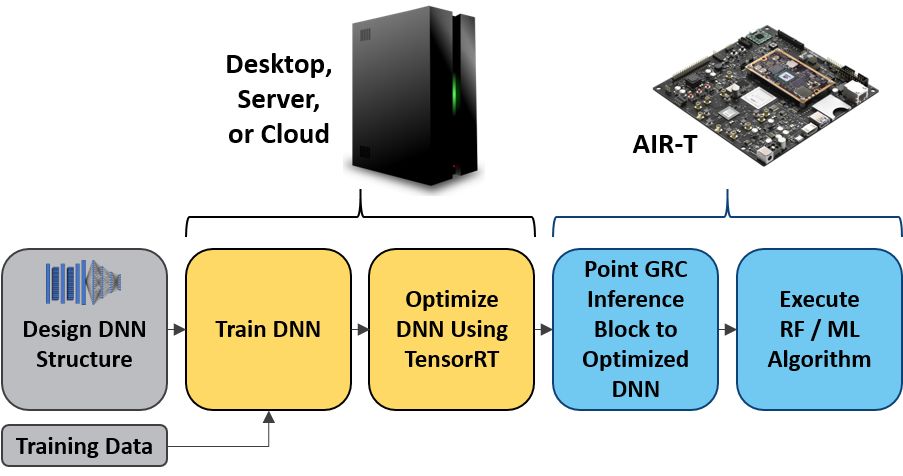
Once an algorithm has been trained (or a pre-trained algorithm has been downloaded), the user will reference it in the Deepwave TensorRT Inference block as shown below. The inference batch size may be less than or equal to the batch size created in the inference engine. It can easily be controlled via the Stream to Vector block, though optimum performance is achieved when the value is set during the optimization step. While all of this may seem a bit difficult at the moment, we assure you that the examples provided with the AIR-T will be more than enough to get you up and running.
GNU Radio Integration
Key to our approach is the integration of our hardware and device drivers with GNU Radio, which is a familiar tool to anyone working in the wireless domain. GNU Radio allows RF experts to tie together blocks of functionality using an intuitive GUI. Many of the “in the weeds” details regarding the software implementation are well abstracted, so the user can focus on the algorithm instead. More information can be found here: https://www.gnuradio.org/.
Our vision for GNU Radio integration is to get to the point where performance of a GNU Radio application is within 10% of the throughput of the same algorithm implemented in C++, with a fraction of the associated development time and cost. We will be the first to acknowledge that we aren’t there yet and there are some challenges with the use of GNU Radio for truly performance-intensive applications. For example, currently to move data to/from a GPU within a GNU Radio block, we have to do two memory copies, which limits throughput in GPU based applications. Currently, this may be overcome by writing custom code, but we will be alleviating this bottleneck very soon. For a vast majority of early adopters the existing level of performance in GNU Radio should be more than sufficient.
In order to make algorithm development more streamlined, we plan to provide a few custom GNU Radio blocks to leverage the hardware on the AIR-T. Namely, here’s what is included:
- A SoapySDR module to allow for communication with the RF hardware (more on this below).
- A CUDA block and associated tutorial to allow for an arbitrary CUDA kernel to be executed from within GNU Radio.
- A cuFFT block for GPU-based Fourier transforms.
- A TensorRT block which allows for optimized machine learning inference to be run on the GPU. Note that TensorRT is compatible with models from many of the most common machine learning frameworks such as TensorFlow, Keras, Caffe, and MATLAB.
These blocks allow you to get the most out of the hardware on the AIR-T without the hassles of having to communicate with the hardware directly. Spend your time focusing on the algorithm, not the hardware integration.
SoapySDR Integration
On the topic of device drivers, we abstract away all of the RF related hardware into a SoapySDR device module. Talking to the various device drivers individually is still available as an option for those who are interested (e.g., if you have custom firmware you want to host on the FPGA), but is definitely not a requirement to get up and running.
SoapySDR is a framework that provides a standardized API for SDRs, abstracting away much of the hassle with directly talking to things like RFICs, FPGAs, etc. For example, you don’t need to worry about what binary stream to send over the serial peripheral interface (SPI), instead you can call a function like setFrequency(). More information can be found here: https://github.com/pothosware/SoapySDR/wiki or https://github.com/pothosware/SoapySDR/wiki#client-api.
Deepwave plans to provide a SoapySDR module that handles all the nuances of talking to individual device drivers. As a result, we will be able to leverage the power of the SoapySDR framework, which includes GNU Radio integration via source and sink blocks to talk to the hardware. Additionally, this allows anyone who has previously deployed an algorithm on a different set of hardware to easily have their code run on the AIR-T, provided that their hardware can also communicate via SoapySDR or one of the many available wrappers. As an example of the flexibility of SoapySDR, it provides a wrapper for the popular USRP Hardware Driver (UHD). Therefore, if you have an algorithm that currently uses National Instruments hardware, you will be able to run it on the AIR-T with minimal (if any) code changes.