You may have noticed in our campaign material we are very modest about the Ten64’s network abilities - we also hinted about future scalability using technologies such as DPDK, XDP, and AIOP.
Ten64 does 10G throughput today - but we believe there is quite some room for improvement since the Linux network stack doesn’t use the hardware as efficiently as possible.
What are my options for 10G on Ten64?
There have been a few comments about how Ten64 would be better if it was 8 x 2.5G or had more 10G ports. We would love to do that! However, we don’t think the 2.5/5/10GBase-T offerings on the market allow us to do that right now - and offer it for a price that would be acceptable.
There is some movement on 2.5GBase-T; since it works over existing Cat5e, there is more momentum behind it. With 5GBase-T and above, there are not yet enough options to ensure price competition in the market. To offer a hypothetical "8x2.5G" configuration, we would need a switch IC that offers multiple 2.5G lanes - a few of these exist, but not at a price point or in a form factor on the same magnitude as gigabit ones.
Here are your current options:
Use 10G SFP+ direct attach cables (or fiber)
This is the best option for connecting to 10G switches and servers and has very low power consumption. If your primary goal is to connect the the Ten64 to a nearby desktop or server, there are many SFP+ adaptors on the secondary market (such as the Intel X520) available quite cheaply.

Use a 10GBase-T SFP transceiver
SFP transceivers are also widely available in the secondary market. For example, the Mikrotik S+RJ10 is a multi-rate SFP transceiver that supports 1G, 2.5G, 5G, and 10GBase-T SFP. It has internal buffers that allow it to work with a 10G interface on the board side, so that, regardless of the link partner rate, you don’t need to reconfigure Ten64 to expect a 1G or 2.5G SFP. In addition, it uses flow control to signal Ten64 not to supply packets faster than the connected client can handle.
A word of caution: 10GBase-T SFP’s tend to run quite hot. We have found they work most reliably in the upper SFP+ slot in the Ten64. Some manufactuers do not recommend using two of them stacked vertically. Please see our hardware compatibility list for more information.

Can I route or bridge 10G on a Ten64 right now?
Yes, but there are some caveats:
Limitations due to flow distribution
Traditional Linux routing will at best achieve 3 Gbit/s on a single flow and is not always consistent when more flows are added. This is due to how incoming packet flows are load balanced across cores. For example, a second parallel download may get assigned to the same core as the first, meaning it might only run at 1 Gb/s instead of 3 Gb/s.
Flow distribution is based on hashing packet details such as source and destination IP addresses and ports, so it is not deterministic for lower flow counts. On the other hand, if you have many flows coming in and out of the router, such as in an office situation with many client PCs, distribution will be more equitable.
Limitations due to using all ten Ethernet ports
When all ten Ethernet ports are enabled, performance is slightly limited since the DPAA2 hardware has a reduced set of resources to classify incoming flows and distribute them evenly to all the cores. If you don’t need to use all ten Ethernet ports (both 1G and 10G) simultaneously, you can better optimize your settings.
For typical connections currently available, and their upgrades being deployed in the near future (e.g., 2.5GBase-T, extended spectrum DOCSIS 3.1 and 5G), we can meet these needs today. But we aren’t going to stop there.
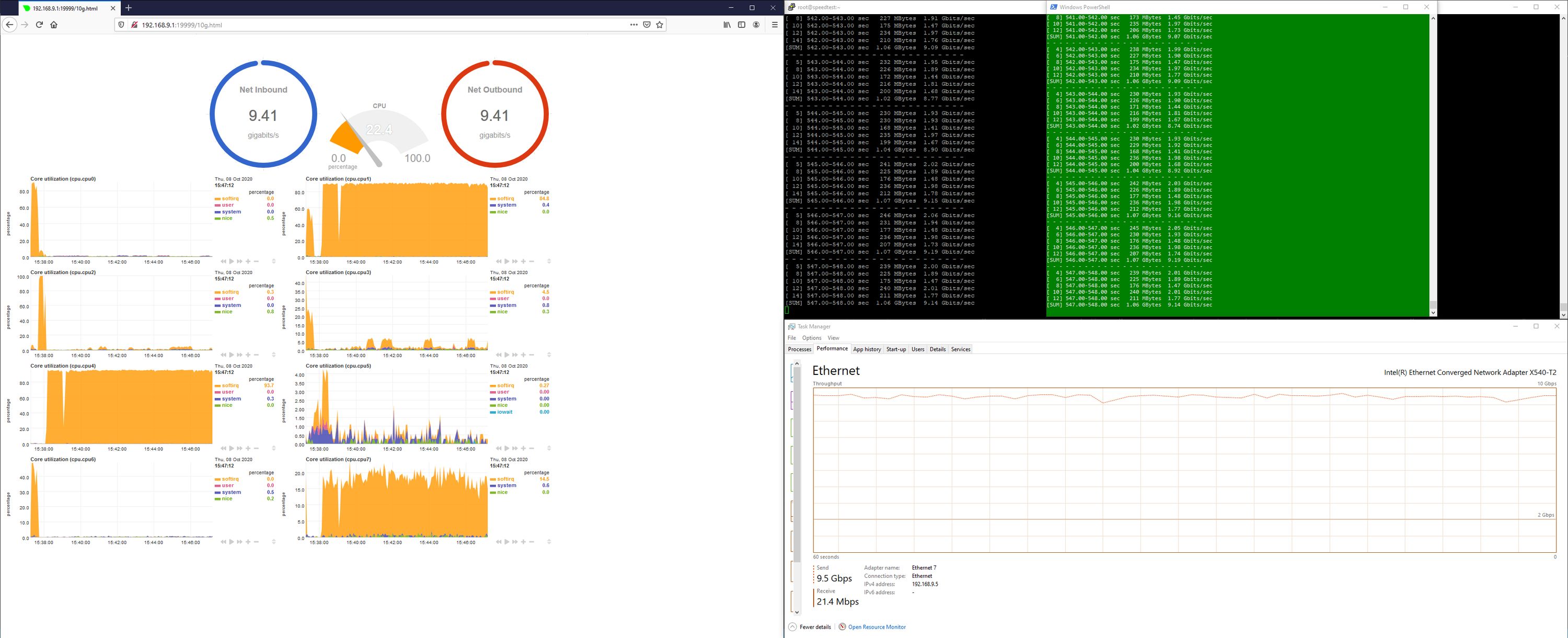
Benchmarks
We did two performance tests to obtain benchmarks. We used iperf3 to measure throughput when a Ten64 is between the iperf3 client and server.
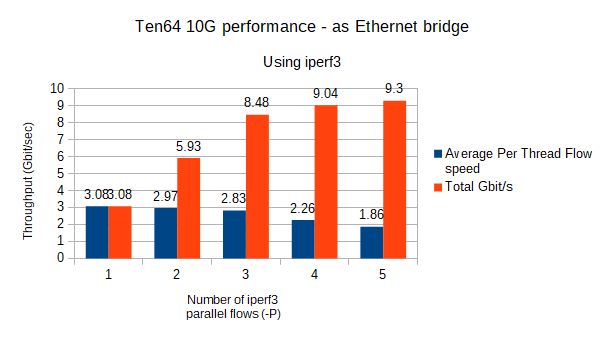
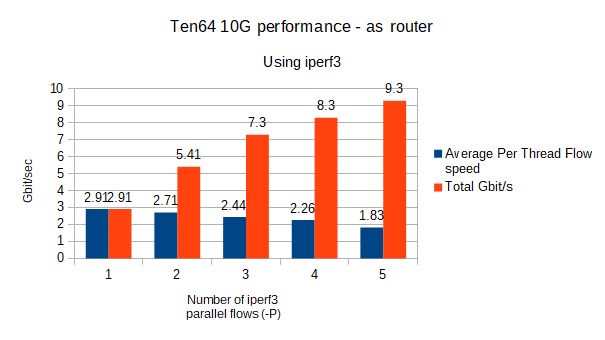
These benchmarks are under optimal conditions, where only three ports (1x1G + 2x10G) are enabled. To give you a rough idea, these two systems, when connected directly (via "crossover" cable) will score about 5-6 Gbit/s on a single iperf thread.
You can view the full results table at our documentation site. Other benchmarks (such as IMIX) will be added in the near future.
I want more throughput (and less CPU usage), what improvements are possible?
Kernel bypass (e.g., DPDK)
The favored industry solution is to bypass the kernel entirely and use a fast network stack in user space. Data Plane Development Kit is the most widely known such tool. DPDK takes control over the network device and typically uses a poll-mode driver (PMD) mechanism. This means it constantly polls the network device to see if new frames are available for processing. At very high packet rates, this is actually faster than waiting for interrupts to be issued by the network device.
Using DPDK’s testpmd application - which sets up a Layer-2 bridge between two ports and only a single core - we can see quite an improvement in single-flow performance, almost up to the "native" level of directly connected systems.
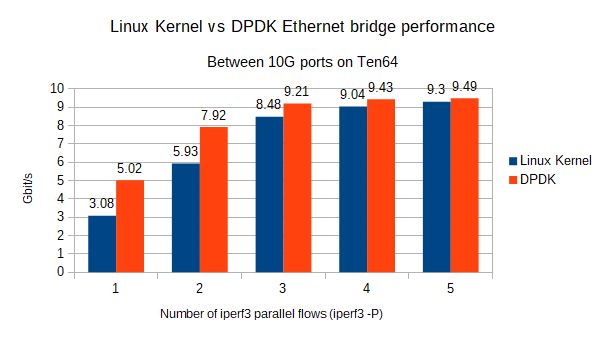
NXP maintains the DPDK implementation for Layerscape SoC’s, as well as related packages such as VPP and DPDK-enabled OpenVSwitch.
As DPDK runs entirely in userspace, we can see this reflected in the CPU usage graphs:
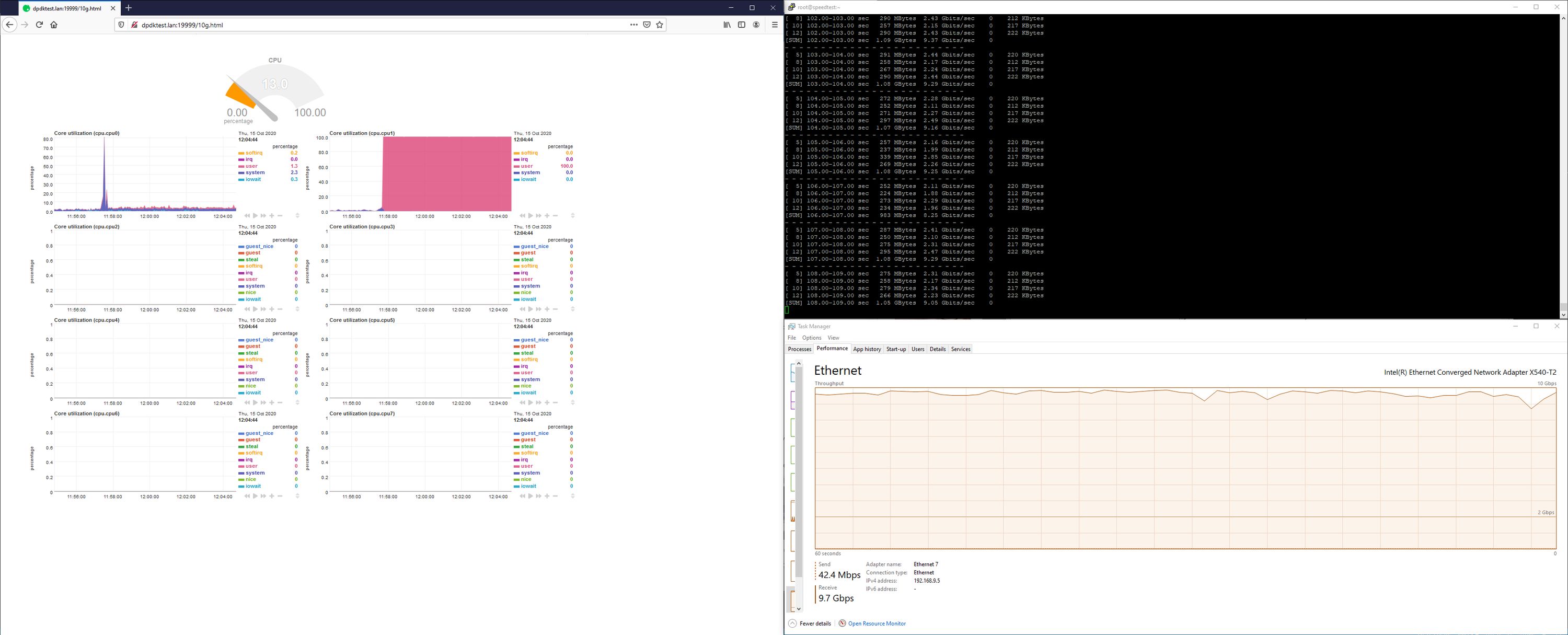
There are some major (but not insurmountable) hurdles to using DPDK:
- As mentioned above, DPDK takes over the entire network device; there will no longer be an
ethXinterface available in Linux. Host/userspace access to the DPDK data plane is typically via tun/tap interfaces so you won't be able to useethtoolor other tools that provide visibility into the physical hardware. - Your entire network stack has to use the DPDK API. Solutions include OpenVSwitch-DPDK for Layer 2, Layer 3 needs a package like DANOS.
- You need to dedicate one or more cores to DPDK to do its polling and servicing of packets.
- You also need to dedicate a portion of memory (via
hugetlb) to DPDK.
But, if your objective is to squeeze the most performance from the hardware - DPDK is the best available solution.
Partial kernel bypass (XDP)
XDP provides a method to hook into the TX and RX packet path of the network driver with eBPF bytecode. It’s not as fast as DPDK, but eliminates many of its downsides. The good news is that the DPAA2 network drivers under Linux do support XDP, though we have not yet conducted a lot of research into this.
Kernel flow offload
In software
The Qualcomm Atheros’ Shortcut forwarding engine provides another partial-bypass solution. This takes the traditional kernel packet processing path out of the picture once the connection is set up and we can be sure that actions such as firewall rules around connection establishment have been followed.
Hardware offload
Hardware flow offload is a widely implemented method of improving network performance, especially in residential-grade routers where the processor itself is nowhere near fast enough to move line-rate traffic.
These methods typically involve installing a hook in the Linux netfilter to check which connections have been established and are now passing data. At that point, the hook will pass the connection details (Source and Destination IP:port) to a hardware block which will route the traffic directly between the network ports, while doing any required packet manipulations (decreasing the TTL, NAT translation).
The LS1088 does not have an "out-of-the-box" solution for this yet, which is a good thing, as there is scope to write our own. Together with the standardized netfilter flowtable hardware offload feature introduced recently in Linux, we can avoid the hacks and pitfalls that have caused issues among proprietary vendor implementations.
Inside the LS1088 is a network block called the "Advanced IO Processor" (AIOP). It consists of four PowerPC e200 cores that can run packet processing hooks. Software running on the general purpose ARM cores can communicate with the AIOP to notify it of new traffic flows.
The advantage of this approach is that you can keep using your standard iptables/netfilter stack with all its flexibility. However, we expect the interface between the network and kernel may have to be modified (e.g., presenting the Ethernet ports as a VLAN switch) to accommodate the AIOP "owning" the Ethernet ports.
Roadmap to increasing performance
This is our path to delivering the best performance possible on Ten64 while preserving the software ecosystem we all know and enjoy:
- Short term: use XDP to improve performance
- Long term: build AIOP firmware to do flow offloads, interfacing with the standard Linux mechanisms. This can also be extended to other features, such as Layer 2 switching between ports.
Other types of network acceleration in the LS1088
Some of these will be discussed in later project updates:
- Ethernet virtual bridge (DPDMUX): This can offload the fanout between an "uplink" port and multiple downstream virtual ports (e.g., virtual machines or containers). It is similar to SR-IOV found in server-grade PCI Express network adapters.
- Cryptography acceleration: The LS1088 boasts a crypto-acceleration engine well-suited to IPSec acceleration. The Cortex-A53 cores also implement ARM's cryptography extensions.
Can’t we just use <insert faster CPU>?
Yes. But we should point out, faster processors come with costs: money, PCB footprint, and power consumption, to name a few.
The logical choices are the LS1088’s bigger brothers - the LS2088 and the LX2160, which use the Cortex-A72 core, which provides approximately double the performance per MHz over the A53 (but with an associated doubling of power consumption).
There are smaller, four-core options, such as NXP’s LS1046 and Marvell’s Armada 8000 series, but these "taller" SoCs don’t offer as much of an opportunity to host other workloads on the same system.
| NXP LS1088 | NXP LS2088 | NXP LX2160 | |
|---|---|---|---|
| Cores | 8 x A53 | 8 x A72 | 16 x A72 |
| Operating frequency | 1600 MHz | 2100 MHz | 2200 MHz |
| Approximate TDP | 10-15 W | 35-40 W | 25-30 W |
| Process | 28 nm | 28 nm | 16 nm |
| Package size | 23 mm x 23 mm | 37.5 mm x 37.5 mm | 40 mm x 40 mm |
| Number of pins | 780 | 1292 | 1517 |
| List price (relative) | 1.0x | 2.2x | 3.5x |
In the interest of fairness, both the LS2088 and LX2160 provide a lot more I/O than the LS1088 (e.g., dual-channel DDR4, multiple x8 PCIe lanes, more 10G or higher Ethernet), but cost a lot more. And their larger power requirements and pin counts cost more to support, due to their need for complicated power supply designs and more PCB layers.
Late last week, NXP announced the LX2162 which takes the LX2160 and shrinks it into a 23 mm x 23 mm package (minus some I/O channels), but with significantly more pins than the LS1088, so the issues around board design and power consumption still remain.
There are also reduced-core-count versions of all three families available. Above, we have compared the top line SKU of each. In the end, it makes a lot more sense to improve the efficiency of the software before jumping to a larger processor.