The Libre RISC-V core is planning to deploy an innovative vectorisation system, known as Simple-V. Honestly, it’s not very simple at all!
An Introduction to Simple-V
The principle is straightforward: mark ordinary registers as "vectorised," and when an instruction uses one such "tagged" register, go into a hardware-unrolled version of a software macro loop, issuing otherwise identical instructions with contiguous sequentially-increasing register numbers.
It sounds easy… except that the "tag" table behind the registers has been extended to:
- add predication (switching on and off individual "elements" of the vector)
- change the element width so what was previously a 64-bit ADD can be used to do 16-bit or even 8-bit ADDs
- reordering of the elements, for 2D and 3D arrays and matrices: very useful for in-place transposing for matrix multiplication
- extend the instructions so that they can access up to 128 registers, where previously that was limited to 32 (and only 8 for compressed instructions)
All of these turn out to be important for GPU workloads.
One of the most challenging aspects of Simple-V is that there is no restriction on the "redirection." Whilst one instruction could use register five and another uses register ten, both of them could actually be "redirected" to use register 112, for example. One of those could even be changed to 32-bit operations whilst the other is set to 16-bit element widths.
Our initial thoughts advocated a standard, simple, in-order, SIMD architecture, with predication bits passed down into the SIMD ALUs. If a bit is "off," that "lane" within the ALU does not calculate a result, saving power. However, in Simple-V, when the element width is set to 32-, 16-, or 8-bit, a pre-issue engine is required that re-orders parts of the registers, packing lanes of data together so that it fits into one SIMD ALU, and, on exit from the ALU, it may be necessary to split and "redirect" parts of the data to multiple actual 64-bit registers. In other words, bit-level (or byte-level) manipulation is required, both pre- and post-ALU.
This is complicated!
As part of the initial design of Simple-V, there was an accidental assumption that it would be perfectly reasonable to use a multi-issue execution engine, and to simply drop multiple of those "hardware-loop-unrolled" operations into the instruction queue. This turns out to be a radically different paradigm from standard vector processors, where a loop allocates elements to "lanes," and if a predication bit is not set, the lane runs "empty." By contrast, with the multi-issue execution model, an operation that is predicated out means that the element-based instruction does not even make it into the instruction queue, leaving it free for use by subsequent instructions, even in the same cycle, and even if the operation is totally different. Thus, unlike in a traditional vector architecture, ALUs may be occupied by elements from other lanes, because the pre-existing decoupling between the multi-issue instruction queue and the ALUs is efficiently leveraged.
Simple!
Tomasulo Algorithm and Reorder Buffers
There are many other benefits to a multi-issue microarchitecture, as are being discussed on the Libre RISC-V mailing list. Personally, I favour a modified version of the Tomasulo Algorithm, which includes what is known as a reorder buffer. This algorithm is particularly nice because it was first introduced in 1967, and came to prominence in the early 1990s when Moore’s Law started to hit a speed wall. In particular, that means that 1) it’s commonly taught in universities, and 2) patents on the algorithm have long since expired.
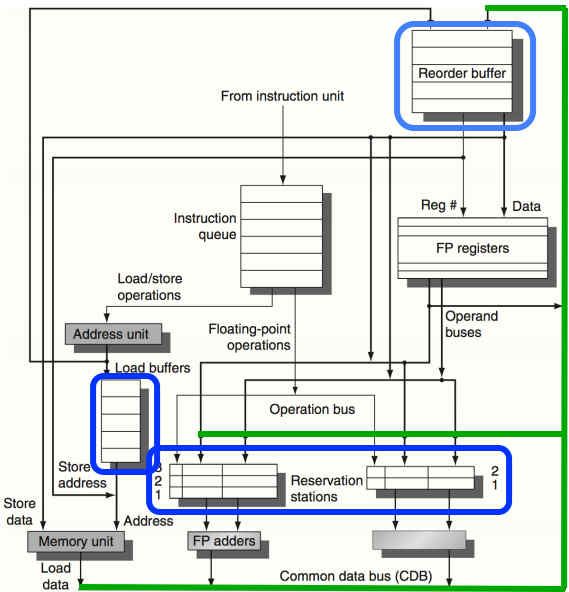
Also, there are both memory hazards and register hazards that a reorder-buffer-augmented Tomasulo algorithm takes care of, whilst also allowing for branch prediction and really simple roll-back, preservation of execution order even though instructions may actually be done out of order, and, crucially, some ALUs may take longer than others, and the algorithm simply does not care. In addition, there may be a really simple way to extend the reorder buffer tags to accomodate SIMD-style characteristics.
We also may need to have simple branch prediction, because some of the loops in Kazan are particularly tight. A reorder buffer (ROB) can easily be used to implement branch prediction, because, just as with an exception, the ROB can to be cleared out (flushed) if the branch is mispredicted. as it is necessary to respect exceptions, the logic has to exist to clear out the ROB: branch prediction simply uses this pre-existing logic.
The other way in which out-of-order execution can be handled is called scoreboarding, as well as explicit register renaming. These schemes seem to have significant disadvantages and complexities when compared to reorder buffers (see upcoming updates for details on how the disadvantages are down to a complete failure of the academic literature to fully comprehend the design of the CDC 6600):
- Explicit register renaming needs a global register file quite a bit larger than the actual one. The Libre RISC-V SoC already has two whopping great 128-entry 64-bit register files.
- In-order scoreboarding actually delays instruction execution (all of it) until such time as the source registers and all other dependencies are ready. The idea seems to be that the register renaming should have taken care of as many of these dependencies as possible, in advance.
- Unlike Tomasulo with reorder buffers, there does not appear to be any assistance in dealing with memory LOAD/STOREs.
- There's no clear way to handle branch prediction, where the reorder buffer of Tomasulo handles it really cleanly.
However, there are downsides to reorder buffers:
- The common data bus (CDB) may become a serious bottleneck, as it delivers data from multiple ALUs which may be generating results simultaneously. To keep up with result generation, multiple CDBs may be needed, which results in each receiver having multiple ports.
- The destination field in the ROB has to act as a key in a content addressble memory (CAM). As a result, power consumption of the ROB may be quite high. It may or may not be possible to reduce power consumption by testing an active bitfield (separate from but augmenting the ROB) to indicate whether destination registers are in use. If inactive, the CAM lookup need not take place.
Whilst nothing’s firmly set in stone, as we have a charter that requires unanimous decision-making from contributors, so far it’s leaning towards reorder buffers and Tomasulo as a good, clean fit. In part, that is down to more research having been done on that particular algorithm. For completeness, scoreboarding and explicit register renaming need to be properly and comprehensively investigated.
Scoreboarding
Scoreboards are an effort to keep "score" of whether an instruction has all of its operands (and the hardware that uses them) ready to go, without conflict. Everything about the scheme, unfortunately, says that it is an incomplete mechanism. Unlike the Tomasulo algorithm when augmented with a reorder buffer, there’s no way to "undo" a completed operation: the operation proceeds and modifies registers or memory, in an out-of-order fashion, regardless of consequences. If an exception occurred, tough!
Hence, it was quite hard to accept scoreboarding enough to understand it. It wasn’t until this mailing list message that I realised that there is near-direct equivalence between the features of scoreboarding and the Tomasulo algorithm. It’s not complete equivalence, because the reorder buffer is what keeps everything transactional and clean. However, at least the scoreboard does have direct equivalence to the reservation station concept: the scoreboard records whether the source registers are ready or not (and so does the reservation station).
The problem is: there are far too many things missing from the scoreboard concept:
- Register-renaming has to be done separately (the Tomasulo reservation stations, in combination with the ROB, handle that implicitly).
- Scoreboarding introduces the concept of "waffly exceptions" (the ROB can even record exceptions that are only actioned if they make it to the head of the queue).
- Scoreboarding does not provide a means to do multi-issue (the ROB does: you just put more than one entry per cycle into the buffer).
(Note: in later updates, we find that, fascinatingly, these things are just not true.)
Unanimous Decision Making
The project is being run along ethical lines. That in particular means unanimous decision-making. Nobody gets to over-rule anyone else: everyone matters, and everyone’s input matters. So if I think Tomasulo is better, it’s up to me to keep on researching and evaluating and reasoning until I have convinced everyone else… or they have convinced me otherwise.
I have it on good authority from some extremely comprehensive research that this is a hell of a lot better way to do decision-making than "mob-rule" voting. "Mob-rule" voting (a.k.a. "democracy") basically automatically destroys the morale and discounts the will of the "minority." No wonder democratic countries have minority representation political groups, because it’s heavily brainwash-ingrained into people living in such countries that the minority view shall be disregarded; of course they feel the need to shout and get angry!
I feel learning from these mistakes, which are often copied and reflected in software libre groups, is very important, to try something different. In previous libre projects that I’ve run, I was the kind-of informal "technical lead," where I never actually defined any guidelines or rules about how the project should make decisions: basically, I let people do what they liked unless it disrupted the project for everyone else. I set myself up as the arbitrator, so to speak. The way that this project will be run is very much new and experimental, even to me. We’ll see how it goes.
Archival purposes only.
This project has been abandoned and will not launch.