Project update 4 of 10
Modernising 1960s computer technology: learning from the CDC 6600
by Luke Kenneth Casson LeightonFirstly, many thanks to Heise.de for publishing a story on this project. I replied to some of the Heise Forum comments, endeavouring to use translation software to respect that the forum is in German.
In this update, following on from the analysis of the Tomasulo algorithm, by a process of osmosis I finally was able to make out a light at the end of the "scoreboard" tunnel, and it is not an oncoming train. Conversations with Mitch Alsup are becoming clear, providing insights that, as we will find out below, have not made it into the academic literature in over 20 years.
In the previous update, I really did not like the scoreboard technique for doing out-of-order superscalar execution, because, as described, it is hopelessly inadequate. There’s no roll-back method for exceptions, no method for coping with register "hazards" (e.g., read after write), so register "renaming" has to be done as a precursor step, no way to do branch prediction, and only a single LOAD/STORE can be done at any one time.
All of these things have to be added, and the best way to do so is to absorb the feature known as the "reorder buffer" (and associated reservation stations) normally associated with the Tomasulo algorithm. At which point, as noted on comp.arch there really is no functional difference between "scoreboarding plus reorder buffer" and "Tomasulo algorithm plus reorder buffer." Even the Tomasulo common data bus is present in a functionally-orthogonal way (see later for details).
The only well-known documentation on the CDC 6600 scoreboarding technique is the 1967 patent. Here’s the kicker: the patent does not describe the key strategic part of scoreboarding that makes it so powerful and much more power-efficient than the Tomasulo algorithm when combined with reorder buffers: the functional unit’s dependency matrices.
Before getting to that stage, I thought it would be a good idea to make people aware of a book that Mitch told me about, called "Design of a Computer: the Control Data 6600" by James Thornton. James worked with Seymour Cray on the original design of the 6600. It was literally constructed from PCB modules using hand-soldered transistors. Memory was magnetic rings (which is where we get the term "core memory" from), and the bootloader was a bank of toggle-switches. The design was absolutely revolutionary: where all other computers were managing an instruction every 11 clock cycles, the 6600 reduced that to four. The 7600, its successor, took that figure even lower.
In 2002, someone named Tom Uban sought permission from James and his wife, to make the book available online, as, historically, the CDC 6600 is quite literally the precursor to modern supercomputing:

I particularly wanted to show the dependency matrix, which is the key strategic part of the scoreboard:
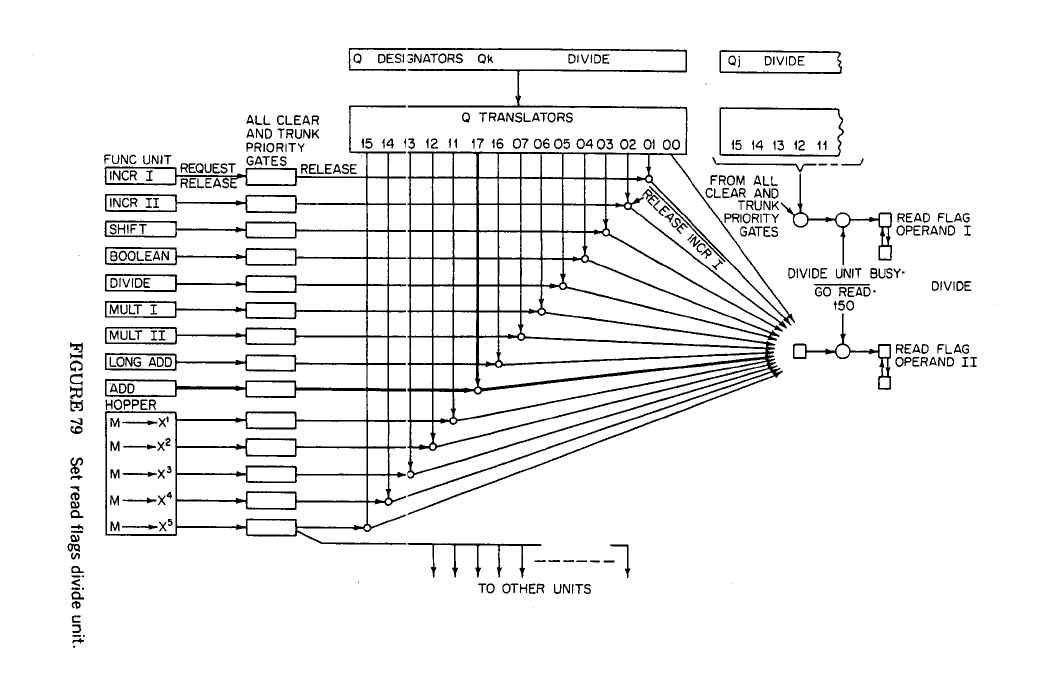
Basically, the patent shows a table with src1 and src2, and "ready" signals: what it does not show is the "go read" and "go write" signals, which allowed an instruction to begin execution without committing execution - a feature that’s usually believed to be exclusive to Reorder Buffers. Furthermore, the patent certainly does not show the way in which one function unit blocks others, which is via the dependency matrix.
It is well known that the Tomasulo Reorder Buffer requires a CAM on the Destination Register, which is power-hungry and expensive. This is described in academic literature as data coming "to." The scoreboard technique is described as data coming "from" source registers, however because the dependency matrix is left out of these discussions (not being part of the patent), what they fail to mention is that there are multiple single-line source wires, thus achieving the exact same purpose as the reorder buffer’s CAM, with far less power and die area.
Mitch’s description of this on comp.arch was that the dependency matrix columns effectively may be viewed as a single-bit-wide "CAM," which of course is far less hardware, being just AND gates. However, it wasn’t until he very kindly sent me the chapters of his unpublished book on the 6600 that the significance of what he was saying actually sank in. Namely, that instead of a merged multi-wire very expensive "destination register" CAM, copying the value of the dependent src register into the reorder buffer (and then having to match it up afterwards on every clock cycle), the dependency matrix breaks this down into multiple really simple single wire comparators that preserve a direct link between the src register(s) and the destination(s) where they’re needed. Consequently, the scoreboard and dependency matrix logic gates take up far less space, and use significantly less power.
Not only that, but it is quite easy to add incremental register-renaming tags on top of the scoreboard + dependency matrix — again, no need for a CAM. Moreover, in the second unpublished book chapter, Mitch describes several techniques that each bring in all of the techniques that are usually exclusively associated with reorder buffers, such as branch prediction, speculative execution, precise exceptions, and multi-issue LOAD/STORE hazard avoidance. The diagram below is reproduced with Mitch’s permission:
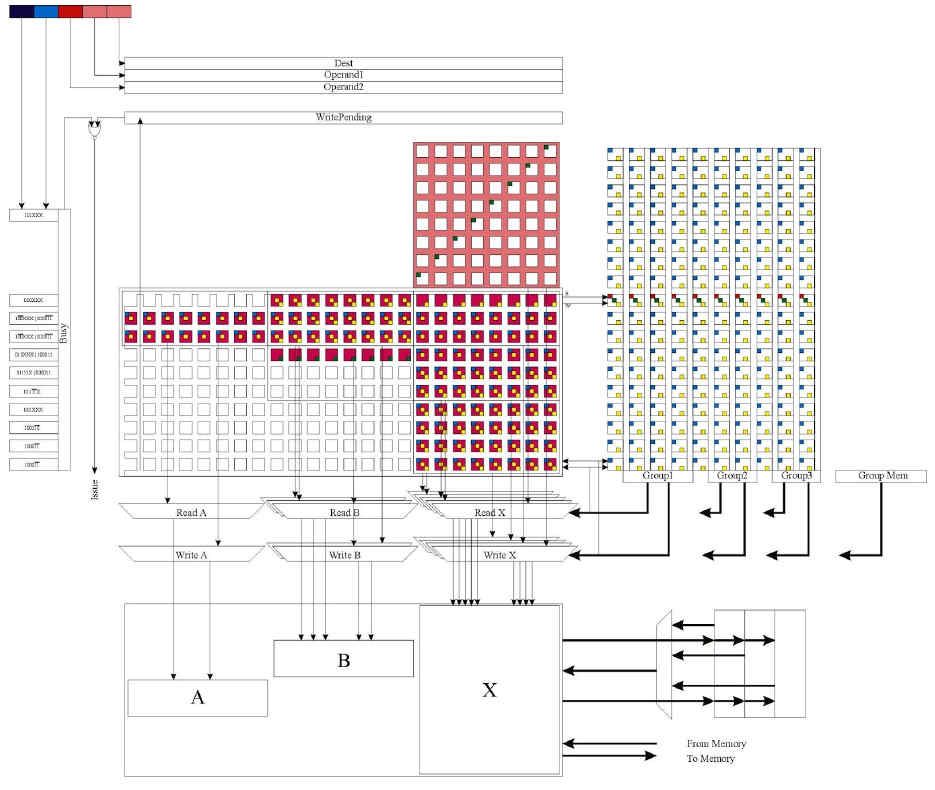
This high-level diagram includes some subtle modifications that augment a standard CDC 6600 design to allow speculative execution. A "Schroedinger" wire is added ("neither alive nor dead"), which, very simply put, prohibits function unit "write" of results (mentioned earlier as a pre-existing under-recognised key part of the 6600 design). In this way, because the "read" signals were independent of "write" (something that is again completely missing from the academic literature in discussions of 6600 scoreboards), the instruction may begin execution, but is prevented from completing execution.
All that is required to gain speculative execution on branches is to add to the dependency matrix one extra line per "branch" that is to be speculatively executed. The "branch speculation" unit is just like any other functional unit, in effect. In this way, we gain exactly the same capability as a reorder buffer, including all of the benefits. The same trick will work just as well for exceptions.
Mitch also has a high-level diagram of an additional LOAD/STORE matrix that has, again, extremely simple rules: LOADs block STOREs, and STOREs block LOADs, and the signals "read / write" are then passed down to the function unit dependency matrix as well. The rules for the blocking need only be based on "there is no possibility of a conflict" rather than "on which exact and precise address does a conflict occur". This in turn means that the number of address bits needed to detect a conflict may be significantly reduced, i.e., only the top bits are needed.
Interestingly, RISC-V "fence" instruction rules are based on the same idea, and it may turn out to be possible to leverage the L1 cache line numbers instead of the (full) address.
Also, Mitch’s unpublished book chapters help to identify and make clear that the CDC 6600’s register file is designed with "write-through" capability, i.e., that a register that’s written will go through on the same clock cycle to a "read" request. This makes the 6600’s register file pretty much synonymous with the Tomasulo algorithm’s "common data bus." This same-cycle feature also provides operand forwarding for free!
This is just amazing. Let’s recap. It’s 2018, there’s absolutely no Libre SoCs in existence anywhere on our planet of 8 billion people, and we’re looking for inspiration on how to make a modern, power-efficient 3D-capable processor, only to find it in a literally 55-year-old design for a computer that occupied an entire room and was hand-built with transistors!
Not only that, but the project has accidentally unearthed incredibly valuable historic processor design information that has eluded the Intels and ARMs (billion-dollar companies), as well as the academic community, for several decades.
I’d like to take a minute to especially thank Mitch Alsup for his time in ongoing discussions, without which there would be absolutely no chance I could possibly have learned about, let alone understood, any of the above. As I mentioned in the very first project update: new processor designs get one shot at success. Basing the core of the design on a 55-year-old, well-documented, and extremely compact and efficient design is a reasonable strategy: it’s just that, without Mitch’s help, there would have been no way to understand the 6600’s true value.
The bottom line is, we have a way forward that will result in significantly less hardware and a simpler design, using a lot less power than modern designs, yet providing all of the features normally the exclusive domain of top-end processors, all thanks to a refresh of a 55-year-old processor and the willingness of Mitch Alsup and James Thornton to share their expertise with the world.
Archival purposes only.
This project has been abandoned and will not launch.