Luxonis
Video & Cameras
MacroFab
DepthAI
An embedded platform for combining Depth and AI, built around Myriad X

Luxonis
Video & Cameras
MacroFab
DepthAI is a platform built around the Myriad X to combine depth perception, object detection (neural inference), and object tracking that gives you this power in a simple, easy-to-use Python API. It’s a one-stop shop for folks who want to combine and harness the power of AI, depth, and tracking. It does this by using the Myriad X in the way it was intended to be used - directly attached to cameras over MIPI - thereby unlocking power and capabilities that are otherwise inaccessible.

Object Detection is a marvel of Artificial Intelligence/Machine Learning. It allows a machine to know what an object is and where it is represented in an image (in ‘pixel space’).
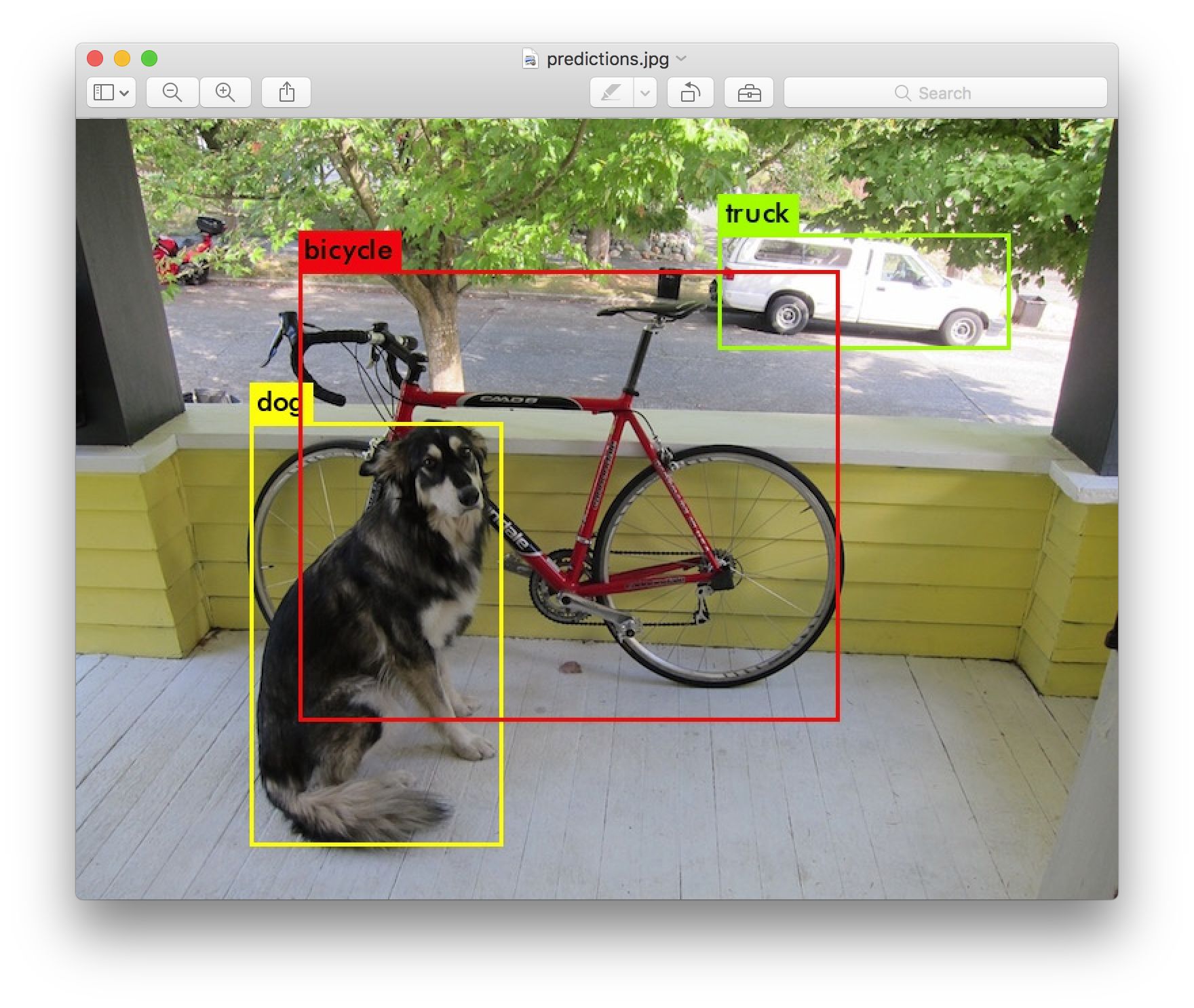
Back in 2016, such a system was not very accurate and could only run at (rougly) one frame every six seconds. Fast forward to 2019, and you can run at real-time on an embedded platform - which is tremendous progress! But, what good does knowing where an object is in an image in pixels do for something trying to interact with the physical world?
That’s where object localization comes in. Object localization is the capability to know what an object is and where it is in the physical world. So, its x, y, z (cartesian) coordinates in meters.
This is what DepthAI allows. At 25 FPS.
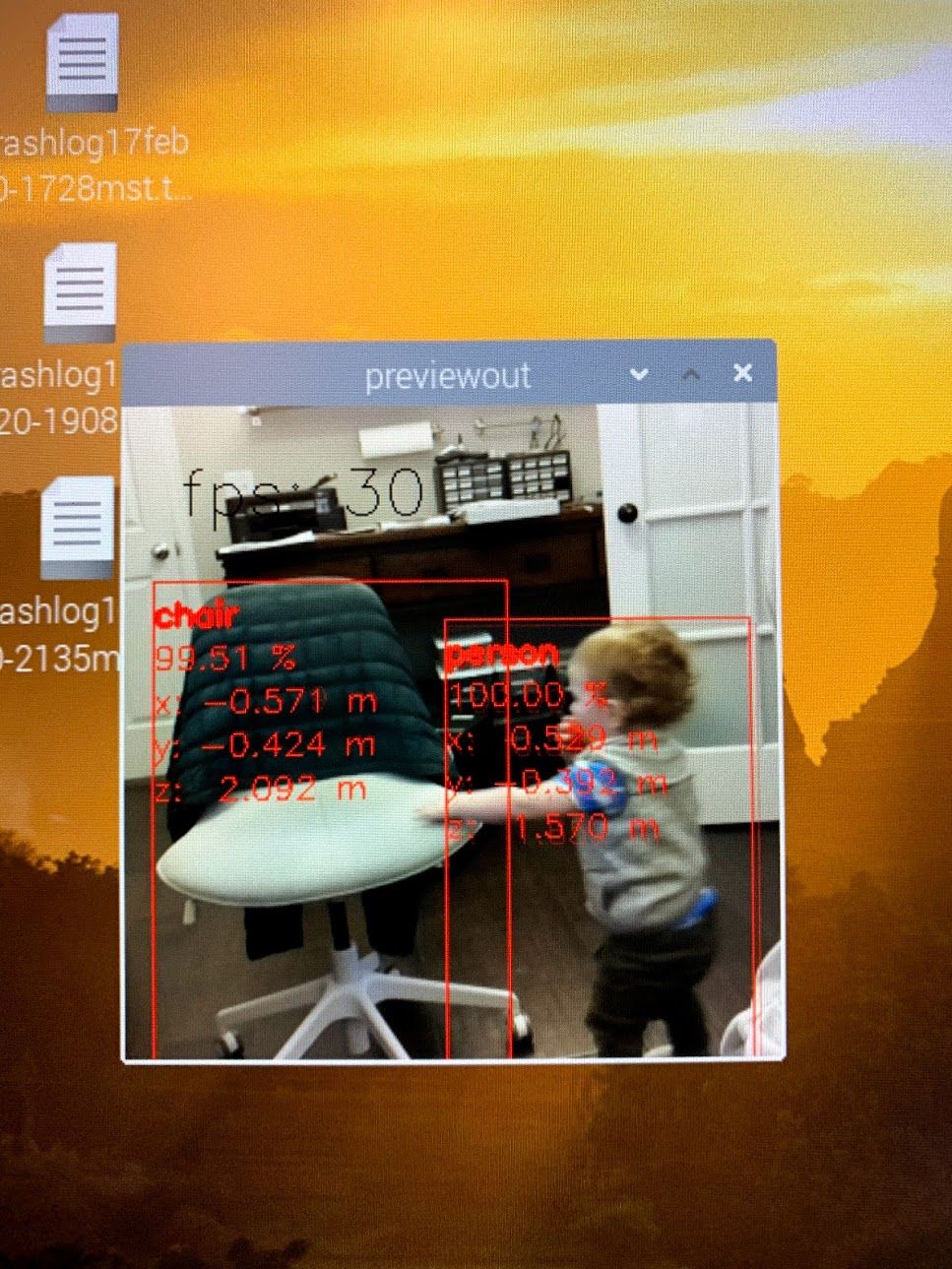
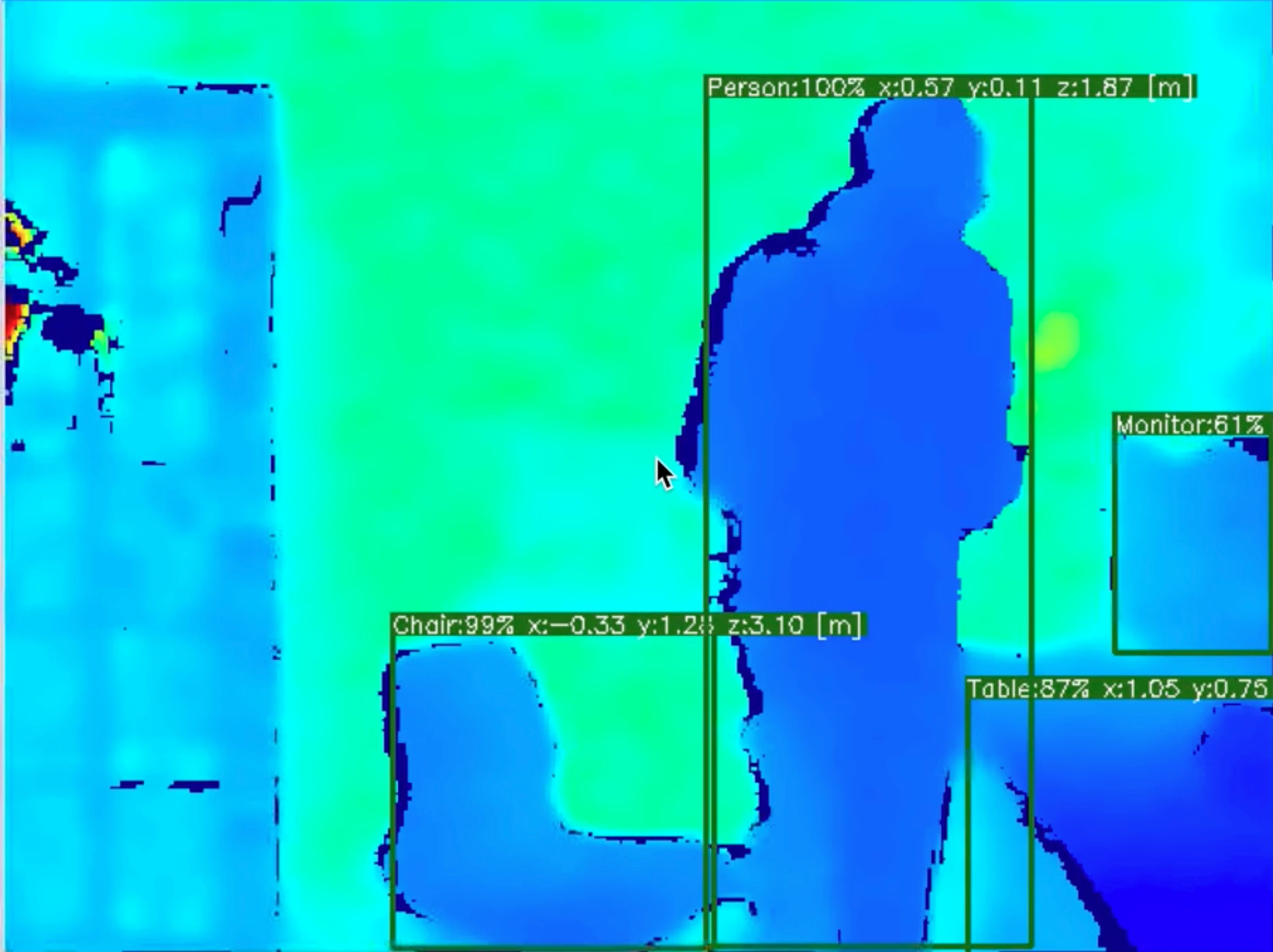
The visualization above shows the object position in meters (the centroid of the object in this case), what it is (e.g., Person, Chair, etc.) and also shows the full front-contours of these objects (visualized with heat-map).
So what is this useful for?
Anything that needs to interact with the physical world. Some examples include:
Health and Safety: Is that truck on a trajectory to run me over? (i.e., Commute Guardian)
Agriculture: Where are the strawberries in physical space and which ones are ripe?
Manufacturing: Where are the faulty parts exactly? So a robot arm can grab them or a flap can knock them into a rework bin.
Mining: Where is the vein? Self-directed and self-stopping based on what is being found and where.
Autonomy: For vehicular platforms or for helping the sight-impaired improve their autonomy (e.g., imagine audible feedback of ‘there is a park bench 1.5 meters to your right with five open seats’).
Existing solutions that utilize the incredible power of real-time object localization have had to implement their systems with a heavy dose of systems engineering at the hardware level, software level, and at the kludge-it-together wiring level.
This is where DepthAI comes in. It is engineered from the ground up, with custom hardware, firmware, and an elegant, easy-to-use Python interface that allows you to easily leverage this insane power. We’ve designed our DepthAI product family to be easy to use. The easiest-to-use setup is our DepthAI Raspberry Pi Compute Module version, which boots up running Object Localization on 20 classes (PASCAL VOC 2012,:
Person: person.
Animal: bird, cat, cow, dog, horse, sheep.
Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train.
Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor.
Consequently, when you point your DepthAI at these objects, you’ll see (and the Raspberry Pi will have access to, at 25 FPS) each object’s location in meters (centroid is reported, but full contour is accessible via API).
Need other models? You can find pre-trained models here that will work right away. Swap them into the included sample Python script, and boom you’re ready to go.
Need to know where people are and what they’re doing? Download and run the person detection model.
Need to know the location of all the honey bees? Download and run a bee-count model.
Or, if you need something custom, you can train your own models based on available/public datasets and then use OpenVINO to deploy them to DepthAI.
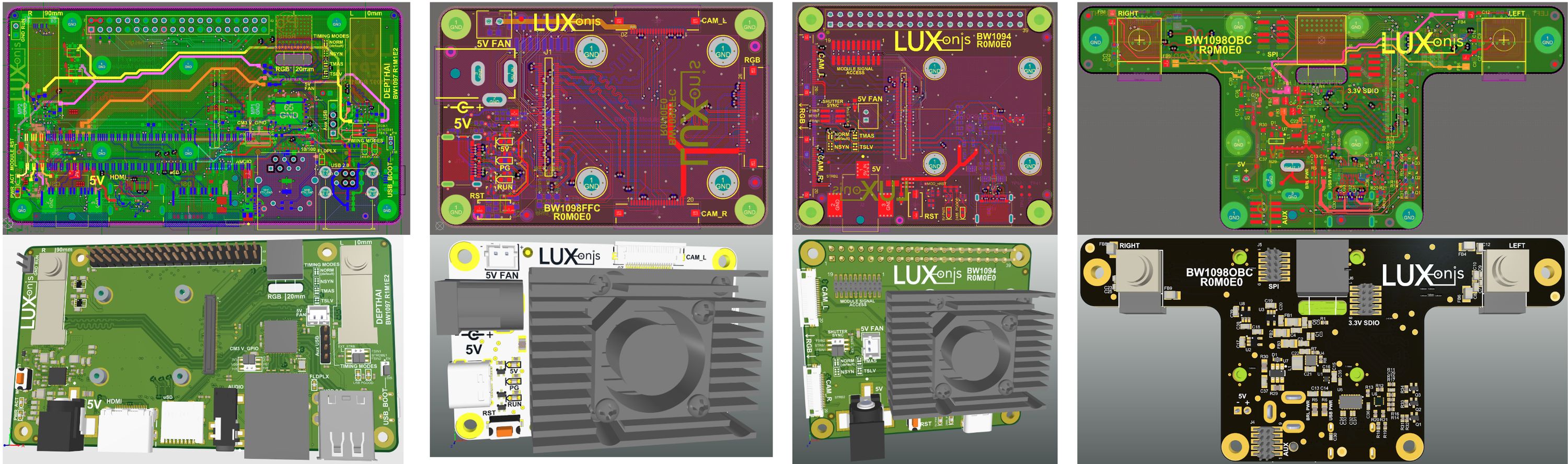
Unlike other solutions, DepthAI is built to integrate into your own products. This starts with our DepthAI module, around which all DepthAI editions (RPi Compute Module, RPi HAT, and USB3) are built:

The module makes what is otherwise a very-difficult-to integrate System on Chip into a drop-in module. All power supplies, sequencing, and monitoring is on-board. And so is all the required clock and driver circuitry. All that’s required of a base board is to provide power and connectivity to cameras.
Once our funding goal is hit, the source designs for all three versions (Raspberry Pi Compute Module, Pi HAT, and USB3) of the carrier boards will be released to backers to allow quick and easy modification of these qualified designs to meet your needs. We’ll also throw in some additional designs to help jump-start integration. Specifically, the following designs will be included should this campaign reach its funding goal:
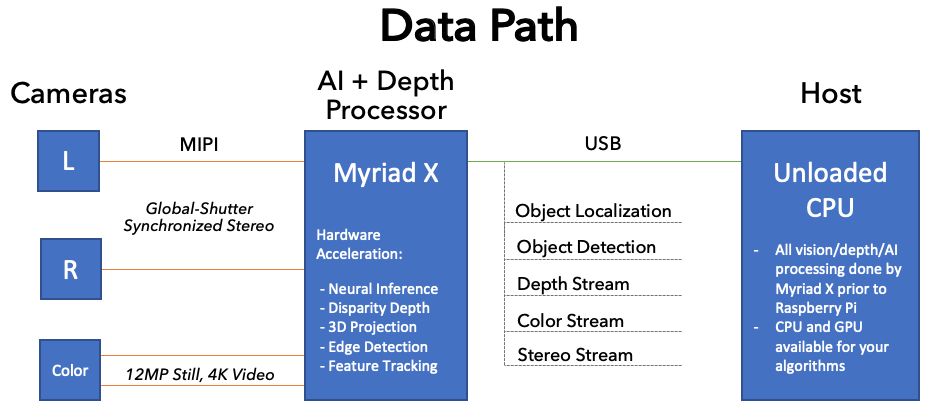
The DepthAI platform does all the heavy lifting of running the AI, generating the depth information and translating it into 3D coordinates, and calculating feature tracking, leaving the host CPU free to run your business logic.
The DepthAI module does all the calculation on-board and outputs the results over USB. These results are retrievable via an easy-to-use Python interface, allowing configuration of which outputs are desired and for which neural model. These outputs include:
Since so much of the processing is done on the DepthAI module (including optionally compressing video), the load on both USB and the CPU is lowered significantly, allowing significantly higher framerates:
Real time object detection with OpenVINO and Movidius
| Pi 3B+, CPU Only | Pi 3B, NCS1, APIv2 | Pi 3B+, NCS1, OpenVINO | Pi 3B+, NCS2, OpenVINO | Pi 3B+, DepthAI, OpenVINO | |
|---|---|---|---|---|---|
| MobileNetSSD (display on) | 0.63 FPS | 3.37 FPS | 5.88 FPS | 8.31 FPS | 25.5 FPS |
| MobileNetSSD (display off) | 0.64 FPS | 4.39 FPS | 6.08 FPS | 8.37 FPS | 25.5 FPS |
(Raspberry Pi/NCS2 data courtesy of the awesome folks over at PyImageSearch, here)
In fact, in many cases UART at a rate of 115,200 baud (which nearly every microcontroller supports) is sufficient, as DepthAI can be configured to return only the object classes and their positions, which even at 30 FPS is ~30 kbps. So you are fee to focus on what your prototype or product needs to do and leave the perception problems to DepthAI.
Let’s look at an example of an autonomous platform:
Say you want to design an autonomous golf-bag caddy. One that follows the golfer, carrying their golf bag, drinks, etc. while obeying the rules of where carts are and aren’t allowed on a course (e.g., don’t follow the golfer into a sand trap or onto the green!). The current RF-based versions of these will follow you right into the sandtrap.
DepthAI can be set to output where the golfer-to-follow is in x, y, z meters away from the robo-caddy. And it can also report on the location and edges of the green, sand-traps, other people, golf-carts, the cart-path, etc. based on the output of a neural model trained on these in combination with this real-time depth perception.
So then a host CPU is free to run the business logic of such a cart… such as: ‘golfer is in a sand trap, wait until golfer exits to resume following’.
Speaking of the CPU being free, here is a comparison of the CPU use of running object detection with a Raspberry Pi + NCS2 vs. RPi + DepthAI:
| RPi + NCS2 | RPi + DepthAI | |
|---|---|---|
| Video FPS | 30 | 60 |
| Object Detection FPS | ~8 | 25 |
| RPi CPU Utilization | 220% | 35% |
The above Pi CPU utilization is with the 60 FPS video possible from DepthAI compared to 30 FPS video when using the Pi camera.
Unleash the Full Power of the Myriad X
Existing solutions interface with the Myriad X over USB or PCIE, leaving the MIPI lanes unused and forfeiting the capability to use the most powerful hardware capabilities of the Myriad X.
DepthAI enables the use of the full power of the Myriad X. This was the sole mission of the DepthAI project and we achieved this through custom implementation at all layers of the stack (hardware, firmware, and software), architected and iterated together to make an efficient and easy-to-use system which takes full advantage of the four trillion-operatations-per-second vision processing capability of the Myriad X.
| Hardware Block | Current Myriad X Solutions | Luxonis DepthAI |
|---|---|---|
| Neural Compute Engine | Yes | Yes |
| SHAVE Cores | Yes | Yes |
| Stereo Depth | Inaccessible | Yes |
| Motion Estimation | Inaccessible | Yes |
| Edge Detection | Inaccessible | Yes |
| Harris Filtering | Inaccessible | Yes |
| Warp/De-Warp | Inaccessible | Yes |
| MIPI ISP Pipeline | Inaccessible | Yes |
| JPEG Encoding | Inaccessible | Yes |
| H.264 and H.265 Encoding | Inaccessible | Yes |
When designing DepthAI, we reached out to everyone who would talk to us to solicit feedback on what features, form-factors, etc. would be most useful. What we heard back was split into three camps in terms of needs:
Out of this feedback, the three DepthAI Editions below were born:



From left; RaspberryPi Compute Module, USB Onboard Cameras, USB3 FFC Cameras edition.
The Raspberry Pi Compute Module Edition comes with everything needed: pre-calibrated stereo cameras on-board with a 4K, 60 Hz color camera and a microSD card with Raspbian and DepthAI Python code automatically running on bootup. This allows using the power of DepthAI with literally no typing or even clicking: it just boots up doing its thing. Then you can modify the Python code with one-line changes, replacing the neural model for the objects you would like to localize.


| A. 720p 120 Hz Global Shutter (Right) | J. 1x Solderable USB2.0 |
| B. DepthAI Module | K. 720p 120 Hz Global Shutter (Left) |
| C. DepthAI Reset Button | L. 4K 60 Hz Color |
| D. 5 V IN | M. RPi 40-Pin GPIO Header |
| E. HDMI | O. RPi USB-Boot |
| F. 16 GB µSD Card, Pre-configured | P. RPi Display Port |
| G. 3.5 mm Audio | Q. RPi Camera Port |
| H. Ethernet | R. Raspberry Pi Compute Module 3B+ |
| I. 2x USB2.0 |
This DepthAI variant gives you the easy and convenience of onboard cameras (stero-pair base line of 7.5cm) with the flexibility of working with any USB host.
Any OS that runs OpenVINO (Mac OS X, many Linux variants including Ubuntu, Yocto, etc., and Windows 10) will work with this version. Choose your own host. This version has the advantage that many of these can be used with a single host, for applications where many angles are needed, or many things need to be watched in parallel (imagine a factory line with twn parallel paths). Since the AI/vision processing is done completely in DepthAI, a typical desktop could handle tens of DepthAIs plugged in (the effective limit is how many USB ports the host can handle).

| R. Right Stereo Camera | S. Reset Switch | ||
| L. Left Stereo Camera | U. USB 3.0 Type-C | ||
| C. Color Camera | P. 5V Power | ||
| X. DepthAI Myriad X System on Module |
Note for those who backed our campaign and remember the ‘Raspberry Pi HAT Edition’: Based on feedback from testing and integrating with the Raspberry Pi, this on-board USB3 edition ended up being the most convenient to use with the Pi. We made this design after the initial campaign, and feedback for it was so overwhelmingly positive (particularly over the Pi HAT) that we decided to replace the Pi HAT with this model entirely.
The USB3 Edition allows you, the expert, to use DepthAI with whatever platform you’d like - and with your own stereo baseline from 1 inch (2.54cm) to 10 inches (25.4cm).
This edition does not come with cameras - you must order them separately, selecting the 12MP color camera, the global-shutter stereo pair, or both options.
Any OS that runs OpenVINO (Mac OS X, many Linux variants including Ubuntu, Yocto, etc., and Windows 10) will work with this version. Choose your own host. This version has the advantage that many of these can be used with a single host, for applications where many angles are needed, or many things need to be watched in parallel (imagine a factory line with twn parallel paths). Since the AI/vision processing is done on the Myriad X, a typical desktop could handle tens of DepthAIs plugged in (the effective limit is how many USB ports the host can handle).

| A. 5 V IN | E. Left Camera Port | ||
| B. USB3C | F. DepthAI Module | ||
| C. Right Camera Port | G. Myriad X GPIO Access | ||
| D. Color Camera Port |
To make producing these various versions easier - and to allow easier integration into your designs - each of these variants share the same DepthAI Module:

This module, coupled with the various design incarnations above, allow DepthAI to be built into products much easier, faster, and with more confidence. The module allows the board that carries it to be a simple, easy four-layer standard-density board, as opposed to the high-density-integration (HDI) stackup (with laser-vias and stacked vias) required to directly integrate the VPU itself.
To further simplify integration, we will be releasing our carrier designs for this module to backers if the campaign is a success, including the RPi Compute Module Edition, RPi HAT Edition, and/or USB3 edition carrier boards above. So this makes custom designs significantly easier, as now it’s just a matter of downloading the source Altium files for any or all of these carrier boards and modifying them to suit your needs. No worries about ‘did I get all the pinouts for the module right?’ or concerns about stackup differences, etc. - all the source files are right there for you to build off.
All DepthAI Editions incorporate the SoM and therefore include the following specifications:
Beyond that, there are some differences in capabilities:
| RPi Compute Module Edition | RPi HAT Edition | USB3 Edition | |
|---|---|---|---|
| DepthAI SoM Onboard | Yes | Yes | Yes |
| Built-in Raspberry Pi Compute Module | Yes | No | No |
| Mounts to Raspberry Pi | No | Yes | No |
| On-board cameras | Yes | No | No |
| Modular off-board cameras | No | Yes | Yes |
| Supports 12 MP, 4K 60 Hz Video | Yes | Yes | Yes |
| Supports 2x 720p, 120 Hz Video for Stereo Depth | Yes | Yes | Yes |


In many applications, great color representation and the capability to digitally zoom is very important. So DepthAI was designed with this in mind to provide the option to have high-resolution, accurate color representation at high frame-rates to boot.

4K, 60 Hz Video
A typical need (and powerful functionality) in computer vision deployments is the capability to decimate a large image, feed that into an object-detector neural network to find the area(s) of interest, and then selectively crop the correct area of the original very-high-resolution image to feed into a different neural network.
Examples of such a flow are:
So DepthAI supports a very high resolution color image sensor for these sorts of applications. So in the last example, not only can you know -where- all the strawberries are in physical space, but you can also get a visual estimate of ripeness and/or defects (note that ‘feeling the strawberry’ is a recommended final step to get a better read on ripeness).
And in applications where depth information is not needed, DepthAI is designed to be just ‘AI’. So pairing the RPi HAT Edition or USB3 Edition with it delivers this functionality (at lower power than anything else on the market and at very high resolution and quality).
For applications where Depth + AI are needed, we have modular, high-frame-rate, excellent-depth-quality cameras which can be separated to a baseline of up to 12 inches (30.5 cm)

720p, 120 Hz Video
These sensors are mono (grayscale), meaning they absorb all visible light (and then some) and don’t have the noise degradation as a result of the debayering necessary for color representation which gives then an inherent advantage in low-light performance. This effect is visible below in a controlled experiment against the iPhone XS MAX (which is an incredibly high performance low-light color camera):

This same advantage in low-light performance, which is the inherent better signal-to-noise properties of mono sensors vs. color sensors, is also key for feature tracking (which is helpful for smoothly tracking objects after they are localized) and also depth performance - as the quality of the depth is directly dependent on matching of features between the two image sensors - and noise reduces the probability of doing that effectively.
So the low-light performance of this sensor plays directly into improved depth perception and object tracking.
To make integration into prototypes easier, and to maximize usability of off-the-shelf hardware when first implementing systems, both the color camera and the global-shutter stereo cameras are designed to share the same board dimensions and mounting coordinates (and even aperture x/y position) as the Rasbperry Pi V2.1 Camera: (Raspberry Pi V2.1 Camera shown in center below)

Currently, the only way to accomplish such Depth + AI functionality is to serve as your own system engineer, combining multiple hardware, firmware, and software solutions from multiple different vendors.
One such technique is to combine the Intel D435 depth camera ($179) and the Jetson Nano Module ($149). So that’s a $328 solution that works well, if you consider having two separate products cabled together pulling pretty significant power OK. It also puts a lot of the depth re-projection onto the CPU of the Jetson Nano (while the GPU runs the neural inference), so if you have application code that needs CPU, you need another processor, or have to deal with low framerate.
The second most popular is to buy a NCS2 ($99), a D435 ($170), and a Raspberry Pi ($35); totalling $304 USD. This is more expensive and a tad slower. Same problem with Raspberry Pi CPU getting taxed so end-user code doesn’t have anywhere to run, really.
| DepthAI | D435 + NCS2 + Raspberry Pi | D435 + Jetson Nano | |
|---|---|---|---|
| Easy Setup & Development | Yes | No | No |
| Efficient Data Path | Yes | No | Yes |
| Real Time | Yes | No | Yes |
| Low Latency | Yes | No | Yes |
| Product-izable | Yes | No | Somewhat |
| CPU Free for User Code | Yes | No | No |
| CPU Utilization | Near-zero | Maxed | Maxed |
| Adjustable Stereo Baseline | Yes | No | No |
| Hardware Depth Projection | Yes | No | No |
| Hardware Vision Accelerator | Yes | No | No |
| Power | 6 W (including Pi) | 7 W | 8 W |
| Price | $299 USD | $314 USD | $328 USD |
| Object Localization Rate | 26 FPS | 3 FPS* | 16 FPS* |
DepthAI unleashes the Myriad X to do depth, AI, and feature tracking all in one module. Most importantly, this allows the solution to ‘just work’, removing the systems engineering and integration work required in the other solutions. Its modular design also allows easier integration into products and prototypes, whether on a manufacturing line, farm equipment, or on the back of a bicycle.
It also leaves any host it may be attached to at 0% CPU use. So not only is it faster, smaller, and easier to integrate, it leaves a home open for your end-use code… the depth, AI, and feature tracking are all 100% on the Myriad X, leaving your host free for -your- code. Our solution is the first to do this.
Our forum is hosted at discuss.luxonis.com, where engineers are active in responding to user questions and often post updates on our progress and questions to help guide our design efforts.
We also have a nascent GitHub repo which will be the host of the Altium design files for the carrier boards and also for the DepthAI software library (with examples).
DepthAI is proudly open source. We will be releasing these design files (hardware and software) upon successful campaign funding.
Here are the product brochures for each of the DepthAI products:
DepthAI was born out of a desire to improve bike safety. Using depth and AI (and feature tracking), we prototyped Commute Guardian, an artificial intelligence bike light that detects and prevents from-behind crashes. Attempting to productize, we realized there isn’t an embedded platform for the required perception. So to make Commute Guardian, we had to make it!


However, we also think the technology we’ve developed with DepthAI could be used to improve projects accross a wide range of industries.
Health and Safety
The real-time and completely-on-device nature of DepthAI is what makes it suitable for new use-cases in health and safety applications.
Did you know that the number one cause of injury and death in oil and gas actually comes from situations of trucks and other vehicles impacting people? The size, weight, power, and real-time nature of DepthAI enables use-cases never before possible.
Imagine a smart helmet for factory workers that warns the worker when a fork-lift is about to run him or her over. Or even a smart fork-lift that can tell what objects are, where they are, and prevents the operator from running over the person - or hitting critical equipment. All while allowing the human operator to go about business as usual. The combination of Depth+AI allows such a system to make real-time ‘virtual walls’ around people, equipment, etc.
We’re planning to use DepthAI internally to make Commute Guardian, which is a similar application, aiming to try and keep people who ride bikes safe from distracted drivers.
Food processing
DepthAI is hugely useful in food processing. To determine if a food product is safe, many factors need to be taken into account, including size (volume), weight, and appearance. DepthAI allows some very interesting use-cases here. First, since it has real-time (at up to 120FPS) depth mapping, multiple DepthAI can be used to very accurately get the volume and weight of produce without costly, error-prone mechanical weight sensors. And importantly, since mechanical weight sensors suffer from vibration error, etc., they limit how fast the food product can move down the line.
Using DepthAI for optical weighing and volume, the speed of the line can be increased significantly while also achieving a more accurate weight - with the supplemental data of full volumetric data - so you can sort with extreme granularity.
In addition, one of the most painful parts about inspecting food items with computer vision is that for many foods there’s a huge variation of color, appearance, etc. that are all ‘good’ - so traditional algorithmic solutions fall apart (often resulting in 30% false-disposal rates when enabled, so they’re disabled and teams of people do the inspection/removal by hand instead). But humans, looking at these food products can easily tell good/bad. And AI has been proven to be able to do the same.
So DepthAI would be able to weigh the food, get it’s real-time size/shape, and be able to run a neural model in real-time to produce good/bad criteria (and other grading) - which can be mechanically actuated to sort the food product in real-time.
And most importantly, this is all quantified. So not only can it achieve equivalent functionality of a team of people, it can also deliver data on size, shape, ‘goodness’, weight, etc. for every good product that goes through the line.
That means you can have a record and can quantify in real-time and over time all the types of defects, diseases seen, packaging errors, etc. to be able to optimize all of the processes involved in the short-term, the long-term, and across seasonal variations.
Manufacturing
Similar to food processing, there are many places where DepthAI solves difficult problems that previously were not solvable with technology (i.e., required in-line human inspection and/or intervention) or where traditional computer vision systems do function, but are brittle, expensive, and require top experts in the field to develop and maintain the algorithms as products evolve and new products are added to the manufacturing line.
DepthAI allows neural models to perform the same functions, while also measuring dimensions, size, shape, mass in real-time - removing the need for personnel to do mind-numbing and error prone inspection while simultaneous providing real-time quantified business isights - and without the huge NRE required to pay for algorithmic solutions.
Mining
This one is very interesting, as working in mines is very hazardous but you often want or need human perception in the mine to know what to do next. DepthAI allows that sort of insight without putting a human at risk. So the state of the mine and the mining equipment can be monitored in real-time and quantified - giving alerts when things are going wrong (or right). This amplifies personnel’s capability to keep people and equipment safe while increasing visibility into overall mining performance and efficiency.
Autonomy
When programming an autonomous platform to move about the world, the two key pieces of info needed are (1) "what are the things around me" and (2) "what is their location relative to me." DepthAI provides this data in a simple API which allows straightforward business logic for driving the platform.
In the aerial use case, this includes drone sense-and-avoid, emergency recovery (where to land or crash without harming people or property if the prop fails and the UAV only has seconds to respond), and self-navigation in GPS-denied environments.
For ground platforms, this allows unstructured navigation: understanding what is around, and where, without a-priori knowledge, and responding accordingly.
A good out-of-the-box example of this is Unfolding Space) (an early tester of DepthAI), which aims to aid in the autonomy of sight-impaired people. With DepthAI, such a system no longer has to be simple ‘avoid the nebulous blob over there’ but rather, ‘there’s a park bench 2.5 meters to your left and all five seats are open’.
Another more straightforward example is autonomous lawn mowing while safely avoiding unexpected obstacles.
DepthAI works with OpenVINO for optimizing neural models just like with the NCS2. This allows you to train models with any popular frameworks such as TensorFlow, Keras, etc. and then use OpenVINO to optimize them to run efficiently and at low latency on DepthAI/Myriad X.
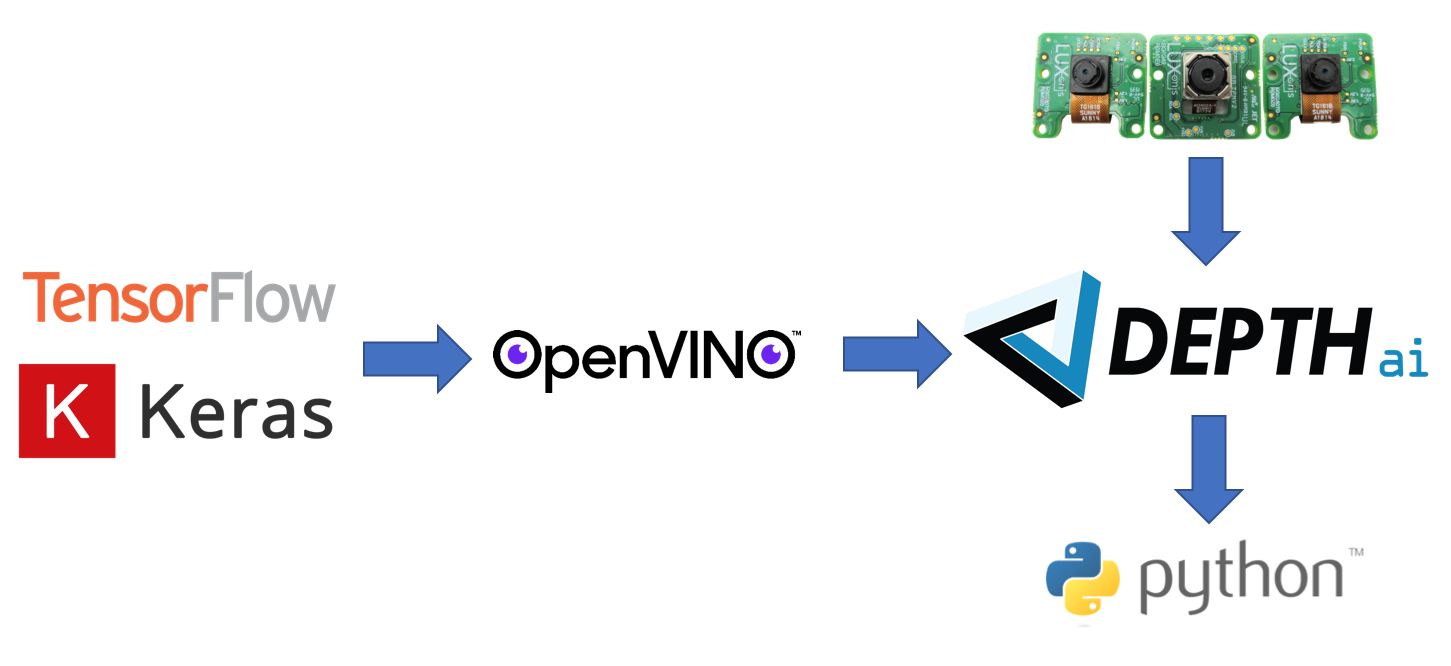
DepthAI then uses this neural model to run inference directly on data streaming from the MIPI cameras, and outputs the results of the inference through an easy-to-use Python API, which is also used to configure the type and format of outputs from DepthAI.
For production, we’ve done a lot of experimentation with PCB fabrication, assembly, and full-product final-assembly and test throughout Colorado (where we’re based), the US more generally (Texas has worked the best), and internationally.
Out of this experimentation we have down-selected KingTop, who is extremely experienced in ultra-fine-pitch BGA and high-density-integration, for volume production and final-product test. We’re also working with several manufacturers in the United States (MacroFab, Colorado Tech Shop, and Slingshot) for smaller runs and prototyping.
Out of this we have produced multiple prototype runs with these local contract manufacturers and larger runs at KingTop.
So far we’ve produced around 200 systems, used in a variety of capacities now from pure test and evaluation, to Alpha testing, to software/firmware development internally and for/with partners.
We are doing this Crowd Supply campaign to support our main production with the goal to get the platform cost low enough that engineers, makers, artists, etc. can buy it directly.
So in short, our goal is to get to significant volumes to make the price as low as reasonably possible, and get the extreme power of Depth + AI in as many hands as possible - hopefully tens of thousands.
So how about schedule?
The main lead-time here is here is lead-time on camera modules at quantity, which is eight weeks. So a 12-week lead time on DepthAI allows eight weeks for the camera modules to be produced, while the PCBAs are being produced and tested in parallel, and then four weeks for final-assembly and test of the DepthAIs with these camera modules.
We plan to deliver DepthAI through Crowd Supply’s fulfillment services, so DepthAI kits will be shipped out from Mansfield, Texas with free delivery within the continental US.
International delivery will incur a surcharge detailed at checkout.
For more information, please see Crowd Supply’s ordering, paying, and shipping guide.
Manufacturing at scale is always a challenge, with problems occurring at high-volumes which were simply not experienced at smaller production. We will do our best to nimbly respond to these problems as they arise and keep to the schedule, while delivering DepthAI at the quality standards we would expect as customers. (We are, and will be, DepthAIs biggest customer on internal Luxonis efforts.)
A second and orthogonal risk is firmware and software feature set and stability. To date we have proven out all the hardware + firmware + software architecture with initial full-stack implementations of all of the DepthAI features (AI with OpenVINO, Depth, 3D re-projection, feature tracking, etc.), and have also started the from-scratch re-write of these implementations with knowledge and lessons-learned from the first-cut proof-of-concept implementations. This two-stage approach has allowed us to have confidence that the hardware design/architecture is sufficient and our final approach to firmware and software architecture works.
In fact, we now have initial functionality of this second-revision of the software initially running, and are working towards feature-complete implementation in a more rigorous and profiled way.
We expect this second revision of the full firmware and software stack to be feature-complete in December, well before the delivery of the first mass-production run, leaving margin for ourselves for any unexpected and time-consuming problems that pop up in such re-writes and optimizations.
Any delays or hurdles that arise will be communicated clearly with backers through project updates.

Produced by Luxonis in Boulder, CO.
Sold and shipped by Crowd Supply.

Complete DepthAI system including Raspberry Pi Compute Module, microSD card pre-loaded with Raspbian and DepthAI Python interface. Boots up running object localization demo. Just connect to power and an HDMI display.

DepthAI for the host of your choice. Runs on anything that runs OpenVINO (a lot of things), including Mac OS X, Linux (Ubuntu 16.04, Ubuntu 18.04, CentOS, Yocto), and Windows 10.

Allows you to integrate the power of DepthAI into your own products. Supports 3 cameras total; dual 720p, 120 Hz Global Shutter and one 4K, 60 Hz Color connected through a 100-pin board-to-board connector. All power conditioning/sequencing, clock synthesis for the Myriad and the cameras, and boot sequencing is included in the module. Just provide 5 V power and physical connections to cameras.



If you don't have an immediate need for DepthAI, but may someday, or want to help us make progress on this depth, AI and tracking platform, please feel free to support us by donating. Thank you! You'll be rewarded with our gratitude and progress updates as the campaign goes on.

DepthAI HAT for Raspberry Pi (3, 3B+, and 4). Add your choice of 12 MP, 4K video color camera module and/or dual-global-shutter 720p mono camera modules for stereo depth and object localization.

Brandon quit his job at Ubiquiti leading the UniFi team in order to focus on embedded machine learning and computer vision. He misses the UniFi team. But he just had to try this, as he thinks it's the future!


