The ‘why’ of the DepthAI (that satisfyingly rhymes) is we’re actually shooting for a final product which we hope will save the lives of people who ride bikes, and help to make bike commuting possible again for many. What we envisioned is a technology-equivalent of a person riding backwards on your bike holding a fog horn and an ambulance-LED strip, who would tap you on the shoulder when they noticed a distracted driver, and would use the LED strip and the horn judiciously to get the attention of distracted drivers - to get them to swerve out of the way.
In working towards solving this problem, we discovered there was no solution on the market for the real-time situational awareness needed to accomplish this. So we decided to make it. In doing that, we realized how useful such an embeddable device would be across so many industries, and decided to build it as a platform not only for ourselves, but also for anyone else who could benefit from this real-time object localization (what objects are, and where they are in the physical world).
Out of this, DepthAI was born:
It’s the platform we will use to develop Commute Guardian (and other applications), and we hope it will be equally useful to you in your prototypes and products.
Some History
Back in late 2018 and early 2019, having already immersed ourselves in all computer vision and machine learning for around a year, it struck us (no pun intended) that there had to be a way to leverage technology to help solve one of the nastier technology problems of our generation:
A small accident, or ‘fender bender’, as a result of texting while driving, often ends up killing or severely injuring/degrading the quality of life of a bicyclist on the other end.
This happened to too many of our friends, colleagues, and Maker Space cohorts.
These ‘minor’ accidents (were they to be between two cars) resulted in shattered hips, broken femurs, shattered disks, a traumatic brain injur, and protracted legal battles with the insurance companies to pay for medical bills.
So how do we do something about it?
The ultimate solution is infrastructure. But even in the Netherlands, one of the most bike-friendly nations on the planet, it took 30 years to get right, and we’re no good at lobbying or talking to the right people to get infrastructure improved or replaced for people who ride bikes.
So how do we, as technologists, do something to try to keep people who ride bikes safe?
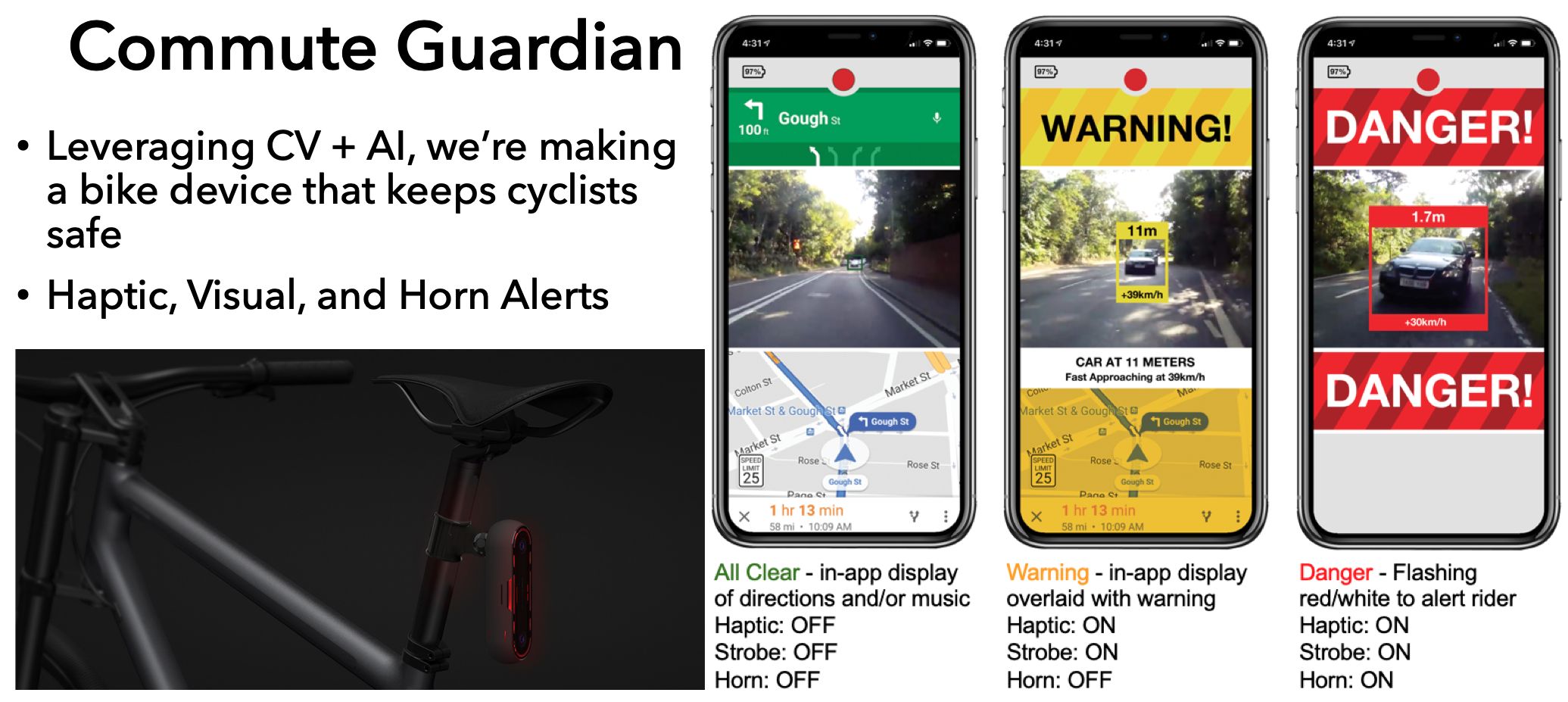
We envisioned leveraging embedded computer vision and machine learning to automatically detect when a driver is on a collision course with you, then pack that functionality into a rear-facing bike light. The final product is a multi-camera, rear-facing bike-light, which uses object detection and depth mapping to track the cars behind you, and determine their x, y, and z position relative to you (plus the x, y, and z of their edges, which is important).


What does it do with this information?
It responds like someone sitting on the back of your bike, looking out for you. It warns you, the rider, while simultaneously taking progessively-more-attention-grabbing action to get the attention of the approaching driver.
Specifically, it is normally blinking or patterning like a normal bike light, but if it detects danger, it initiates up to four actions, in a progressive sequence depending risk:
- Warns you through haptic feedback through the seat post (we know, it sounds funny, but this is the same
technique used in fighter-pilot suits to net fast/intuitive reactions to danger).
2. Starts flashing an ultra-bright strobe to try to get the driver’s attention - a strobe that otherwise would be too energy-draining and/or obnoxious when you’re not in danger.
3. Warns you of danger (with live video) on optional smartphone (iOS and Android) interface. This is for those who mount their phone to their handlebars anyways.
4. Honks a car horn. This is if all else fails, and only happens if you are in certain danger.
Cases 1, 2, and 3 occur when a car is on your trajectory, but has plenty of time and distance to respond.
An example is rounding a corner, where their arc intersects with you, but they’re still at distance. The system will start flashing to make sure that the driver is aware of you, and it will also warn you, the person riding the bike, that you may be in danger and may need to take action.
If the haptic feedback and ultra-bright strobes don’t work to avert the danger, then the system will sound the car horn with enough calculated time and distance left (based on relative speed) for the driver to respond. The car horn is key here, as it’s of only a few ‘highly sensory compatible inputs’ for a driving situation. What does that mean? It nets the fastest possible average response/reaction time.
To show that such a technique would actually work, we prototyped it and ran at vehicles. Here’s such an initial experiment:
What does this show? That it can differentiate between a near-miss and a glancing impact.
What does it not show? Me getting run over… heh. That’s why we ran at the car instead of the car running at us! And believe it or not, this is harder to track because when the car is coming at you, it’s the only thing coming towards you, but when I’m running at the car, the whole world appears to be coming at me, from the perspective of the computer vision. So, it was great it worked well. (And note we intentionally disabled the horn as it’s just WAY too loud inside.)
Long story short, the idea works! Importantly, it worked on the first try - mainly because of how much of a ‘cheat’ it is to use the combination of Depth + AI for perceiving the physical world. It really showcased the power of combining depth perception and AI to understand what’s happening in the world and cemented that value in our minds.
It’s good to note, this only runs at 3FPS because of the inefficiencies of kludging the depth camera, the AI processor, and the Raspberry Pi together - you can see in one instance it’s a little delayed.
DepthAI implements this pile of kludge into one polished solution:
- allowing higher-resolution perception,
- lower power operation,
- high-framerate by fixing the data path,
- offloading the workload from the host (the Pi in this case) to the Myriad X,
- approximately 10-folding the frame-rate,
- while virtually eliminating CPU load (to allow the CPU to run other business logic)
You can see below what the system sees. It’s running depth calculation, point-cloud projection (to get x,y,z for every pixel), and object detection. It’s then combining the object detection and point cloud projection to know the trajectory of salient objects, and the edges of those objects.
This is exactly what DepthAI perceives, but much faster, and without having to systems-engineer multiple pieces of hardware, firmware, and software together to get this perception.
And this is the vehicle-under-test:

We used that for two reasons:
- It was snowing outside, and it was the only one that was parked in such a way indoors that I could run at it.
- It proves that the system handles corner cases pretty well. It's a 'not very typical' car. ;-)
And here’s the hardware used:


The components in the image responsible for the perception are:
- Intel NCS
- Intel D435 Depth Camera
- Raspberry Pi to combine Depth and AI from D435 and NCS respectively (PINTO0309 has a nice starting point on this here)
- 12V-powered USB Hub to connect everything together and run off 12V LiPo battery
- Two car horns (aren't they remarkably small)?
DepthAI takes this pile of hardware and combines it into one solution, architected from the ground up with custom hardware, firmware, and software, so that you can leverage it out of the box in 30 seconds without having to combine hardware or firmware.
Plus, this architecting-from-the-ground-up results in significantly higher performance, lower power, and more flexibility (e.g. capability to set your own stereo baseline from under an inch to up to 12 inches) than combining these off-the-shelf components together.
To put it in pictures, it turns this:

Into this:

If DepthAI is useful to you, or may be in the future, please consider supporting our Crowd Supply campaign today to help bring DepthAI to the world!
Thanks!
Brandon and the Luxonis Team