Project update 6 of 9
HealthyLink Expansion Modules - Edge AI & EEG
by Ashwin WhitchurchHello HealthyPi 6 backers!
In Update 4, we introduced the HealthyLink expansion port—a 62-pin modular interface designed to extend HealthyPi 6’s capabilities. Today, we’re announcing the first two modules that plug into that port: the HealthyLink Edge AI Accelerator for hardware-accelerated ML inference, and the HealthyLink EEG Module for research-grade brain signal acquisition.

Let’s start with the Edge AI Accelerator, powered by STMicroelectronics’ STM32N6 with a dedicated Neural Processing Unit (NPU).
HealthyLink Edge AI Accelerator
| Specification | Value |
|---|---|
| Processor | STM32N657 (Cortex-M55 @ 800 MHz) |
| AI Accelerator | Neural-ART NPU @ 600 GOPS (INT8) |
| Memory | 4.2 MB internal SRAM + 128 MB Octal-SPI Flash |
| Storage | microSD slot via SDMMC |
| Connectivity | USB-C (HS 480 Mbps), CSI camera (RPi-compatible) |
| Host Interface | SPI @ 20 MHz via HealthyLink connector |
| Power | Supplied by HealthyPi 6 main battery |
Performance: 233 ms → <1.5 ms (155x faster)
Our M4 core runs the CVxTz beat classifier at 233 ms per beat—adequate for resting heart rates, but limiting for larger models. The NPU changes that dramatically:
| Platform | Inference Time | Speedup |
|---|---|---|
| M4 (Cortex-M4 @ 200 MHz) | 233 ms ¹ | 1x (baseline) |
| N6 CPU only (Cortex-M55 @ 800 MHz) | ~8 ms | 29x |
| N6 + NPU | <1.5 ms | >155x |
¹ M4 time includes external SDRAM latency for model weights
With 155x headroom over real-time requirements, there’s capacity for multiple models, longer signal windows, or ensemble classification.
Why STM32N6?
We evaluated several MCU-based edge AI platforms before selecting the STM32N6:
- Performance: 600 GOPS NPU outperforms alternatives like MAX78002 while remaining a single-chip solution
- Internal SRAM: 4.2 MB on-chip memory eliminates the external SDRAM latency that slowed our M4 implementation
- Zephyr RTOS: Official mainline support—same toolchain and workflow as HealthyPi 6, no CubeMX/HAL learning curve
- Global availability: STMicroelectronics parts ship through standard distribution worldwide
The STM32N6 hits a sweet spot: fast enough for real-time biosignal inference, simple enough to modify, and available enough to ship.
Why NPU Over CPU?
A CPU handles one calculation at a time. An NPU handles thousands in parallel. CPUs execute instructions sequentially, fetching weights from memory one at a time, while neural networks need massive parallel multiply-accumulate operations.
An NPU is purpose-built for this workload:
- Parallel MAC units: The Neural-ART NPU performs thousands of multiply-accumulate operations simultaneously, compared to sequential execution on a CPU
- Optimized memory access: Weights and activations stream through dedicated pathways, eliminating the cache thrashing that slows CPU inference
- Lower power per operation: Fixed-function silicon doing INT8 math draws a fraction of the power of a general-purpose core doing the same computation
The Neural-ART NPU implements these common neural network operations directly in hardware:
| Operation Type | Hardware-Accelerated Functions |
|---|---|
| Convolution | Conv2D, DepthwiseConv2D, Conv1D (1×1 to 7×7 kernels) |
| Pooling | MaxPool, AveragePool, GlobalMaxPool, GlobalAveragePool |
| Activation | ReLU, ReLU6, LeakyReLU, PReLU, Sigmoid, Tanh, Softmax |
| Normalization | BatchNormalization (fused with Conv) |
| Arithmetic | Add, Multiply, Concatenate |
| Reshape | Flatten, Reshape, Transpose |
Operations not in this list fall back to CPU execution—but for typical CNN architectures like our beat classifier, 95%+ of compute happens on the NPU.
The result: 155x faster inference at similar power. When we ran TinyML inference continuously on the M4, the chip got noticeably warm—all that sequential number-crunching generates heat. The NPU does the same work while barely raising its temperature. For battery-powered wearables, this efficiency translates directly into longer runtime and smaller batteries.
How It Works
When connected via HealthyLink, the Edge AI Accelerator offloads ML inference from the M4—freeing it for real-time signal processing (QRS detection, SpO2, HRV analysis) while the NPU handles neural network inference.

The firmware (app_npu/) runs on Zephyr RTOS with: SPI slave protocol for host communication via IRQ (no polling), ATON runtime for NPU memory management and execution, and dynamic model loading from flash or SD card.
Model Optimization
Getting maximum NPU performance requires optimization. If you’ve wrestled with STM32CubeMX’s labyrinthine menus, you’ll be relieved: ST Edge AI’s web interface is refreshingly straightforward. Upload a model, pick your target, download the result. No 47-step wizard required.
ST Edge AI performs quantization analysis, memory layout optimization, and operator fusion (Conv+BatchNorm+ReLU into single operations). The free Developer Cloud portal requires no local installation—upload TFLite or ONNX, select STM32N657, download optimized C code.
The First Application: Beat Classification
The Edge AI Accelerator ships with the CVxTz beat classifier—a 1D CNN that classifies heartbeats into 5 MIT-BIH categories: Normal (N), Supraventricular (S), Ventricular (V), Fusion (F), and Unknown (Q). The network processes 187 samples (one beat @ 500 Hz) through Conv1D blocks with increasing filter depth, achieving 254K parameters and 6.1M MACs per inference.
After ST Edge AI optimization: model size drops from 291 KB to ~80 KB, tensor arena from 1 MB to ~100 KB—leaving room for larger models or multiple concurrent networks.
Bring Your Own Model
The beat classifier is just a starting point. You can deploy any model that fits within the internal SRAM:
- Train your model in Python (TensorFlow, PyTorch, etc.)
- Export to TFLite or ONNX format
- Upload to ST Edge AI Developer Cloud for optimization
- Copy to SD card or flash via SPI—firmware loads it automatically
We’re also developing a multimodal model that fuses ECG and PPG for rhythm-level arrhythmia detection—cross-modal validation rejects motion artifacts that corrupt single-signal classifiers.
Plug-and-Play Detection
Just like other HealthyLink modules, the Edge AI Accelerator is auto-detected via I2C EEPROM. When you plug it in:
- M7 scans I2C3 bus and reads the module header
- Magic bytes
0x484C4E4B("HLNK") and Module ID0x0005identify the AI Accelerator - M7 loads the HealthyLink AI driver and configures SPI6
- ML inference automatically offloads to the accelerator—no firmware rebuild required
If the Edge AI Accelerator isn’t present, the system falls back to M4-based inference. Same API, same results—just slower.
Why MCU-Based Edge AI?
Why not just use a Raspberry Pi with a Coral accelerator, or an NVIDIA Jetson?
| Platform | AI Performance | Power | Boot Time |
|---|---|---|---|
| HealthyLink Edge AI | 600 GOPS | 0.5 W | <100 ms |
| Coral Dev Board Micro | 4 TOPS | 0.5-1 W | <500 ms |
| NVIDIA Jetson Nano | 472 GFLOPS | 5-10 W | 30+ sec |
| Raspberry Pi 5 + Hailo-8L | 13 TOPS | 5-8 W | 30+ sec |
A Raspberry Pi or Jetson boots in 30+ seconds, draws 5-15 watts, and needs software updates. For ambulatory studies where participants wear devices for 72 hours unsupervised, you need something that just works—no boot screens, no "updating, please wait."
The Edge AI Accelerator powers on in <100 ms, runs 20+ hours on battery, and guarantees deterministic timing. At 0.5 W, the system stays portable with smaller batteries—no bulky power packs required. When a participant presses the power button, the device is recording within a second. For clinical research, this architecture makes the difference between 70% and 95% usable sessions.
What This Unlocks
With <1.5 ms inference and the M4 freed up, new possibilities emerge: AF detection with longer ECG windows, sleep apnea screening with multi-signal fusion, real-time stress detection, and multi-model ensembles running in parallel.
The Edge AI Accelerator can also operate as a standalone inference engine via USB-C—useful for visual AI with the CSI camera, benchmarking custom models, or integrating with other platforms—though its primary role is as a HealthyPi 6 expansion module.
Development Status
| Component | Status |
|---|---|
| Hardware prototype | Complete |
| Zephyr BSP + ATON runtime | Complete |
| SPI slave protocol + M7 driver | Complete |
| Beat classifier (CVxTz) | Ported |
| Multimodal arrhythmia model | Training |
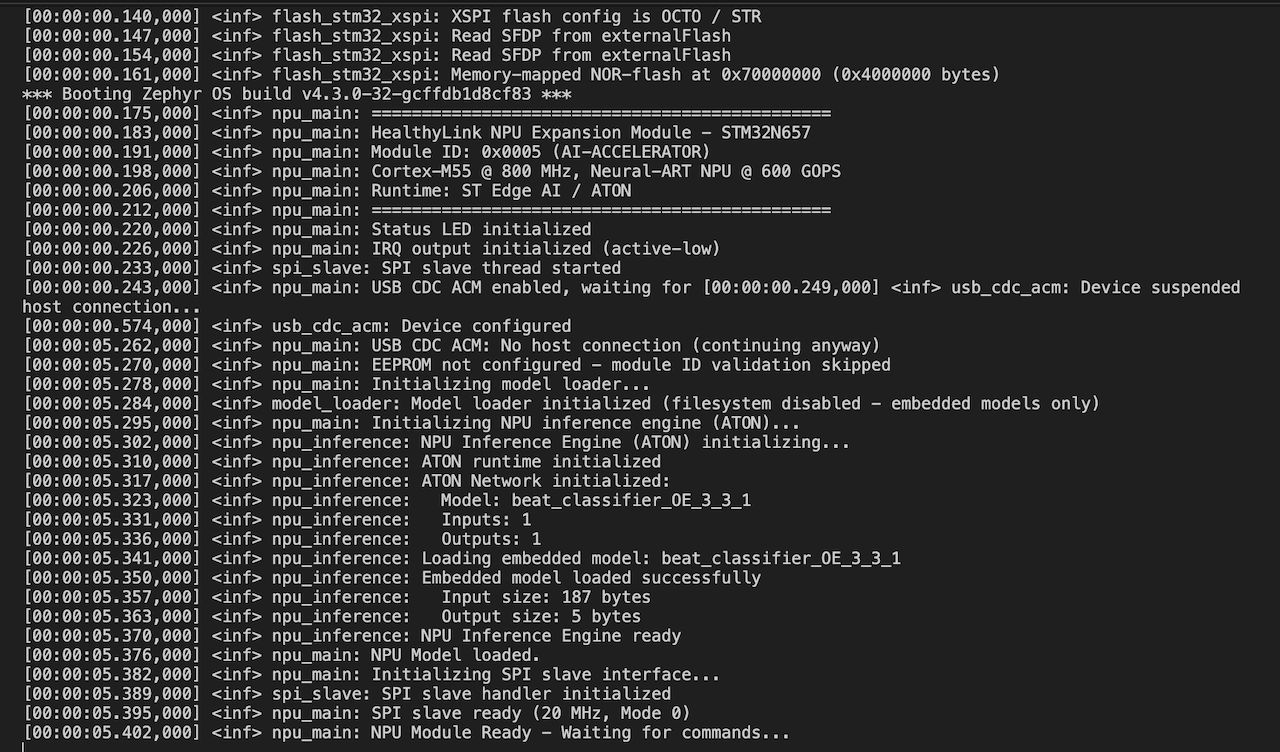
We’ll share detailed documentation, schematics, and the complete firmware source code in an upcoming update. If you have an STM32N6570-DK development kit, you’ll be able to test the inference pipeline on that hardware.
HealthyLink EEG Module

We’re also developing a HealthyLink EEG Module based on the Texas Instruments ADS1299—the same 8-channel, 24-bit AFE used in research-grade EEG systems.
| Specification | Value |
|---|---|
| AFE | Texas Instruments ADS1299 |
| Channels | 8 differential inputs |
| Resolution | 24-bit |
| Sample Rate | 250 / 500 / 1000 / 2000 SPS |
| Input Noise | <1 µVpp |
| Interface | SPI via HealthyLink connector |
| Module ID | 0x0003 (EEG-8CH) |
Applications:
- Sleep studies (polysomnography with ECG + EEG + SpO2)
- BCI research and neurofeedback
- ERP (event-related potential) experiments
- EMG/EOG acquisition
The hardware is ready, but software development is still in progress. We’re working on:
- Zephyr driver for ADS1299 with DMA-based acquisition
- Integration with HealthyPi 6's recording module
- LVGL screens for EEG waveform visualization
We will share more details and the codebase in future updates as the software matures.
The Bigger Picture
HealthyLink isn’t just about adding features—it’s about future-proofing your investment. Today’s Edge AI Accelerator runs beat classification. Tomorrow, with a firmware update and a new model, the same hardware could run sleep staging, stress analysis, or applications we haven’t imagined yet.
This is the power of modular, open-source biomedical instrumentation. The hardware adapts to your research—not the other way around.
Both modules are now available for purchase on Crowd Supply.
Campaign Extended
Since we’re announcing these modules close to the campaign deadline, we’re extending the campaign by 7 days — giving you time to review the specs, ask questions, and decide if they fit your needs.
Questions about the Edge AI Accelerator or ST Edge AI? Let us know! We’re excited to see what the community builds with this new capability.